Intel at ISSCC 2015: Reaping the Benefits of 14nm and Going Beyond 10nm
by Ian Cutress on February 22, 2015 3:00 PM EST
As part of the International Solid-State Circuits Conference every year, Intel brings forward a number of presentations regarding its internal research. The theme this year at ISSCC is ‘Silicon Systems – Small Chips for Big Data’, and Intel previewed a number of their presentations with the media and analysts last week before the conference. Hot topics being talked about include developments for 14nm features that could potentially be ported to real world devices, technological developments at 22nm using Tri-Gate CMOS for adaptive, autonomous and resilient systems and also a few quick words regarding 10nm and beyond.
Taking Moore’s Law Beyond 10nm
Part of ISSCC will be a round table with representatives from Intel, Qualcomm, a couple of industry companies and university researches discussing how 10nm will attack Moore’s Law and how it can be extended below to 7nm. The graphs shown at IDF 2014 make their presence again, showing cost per square mm and cost per transistor, courtesy of Mark Bohr (Intel Senior Fellow, Logic Technology Development):
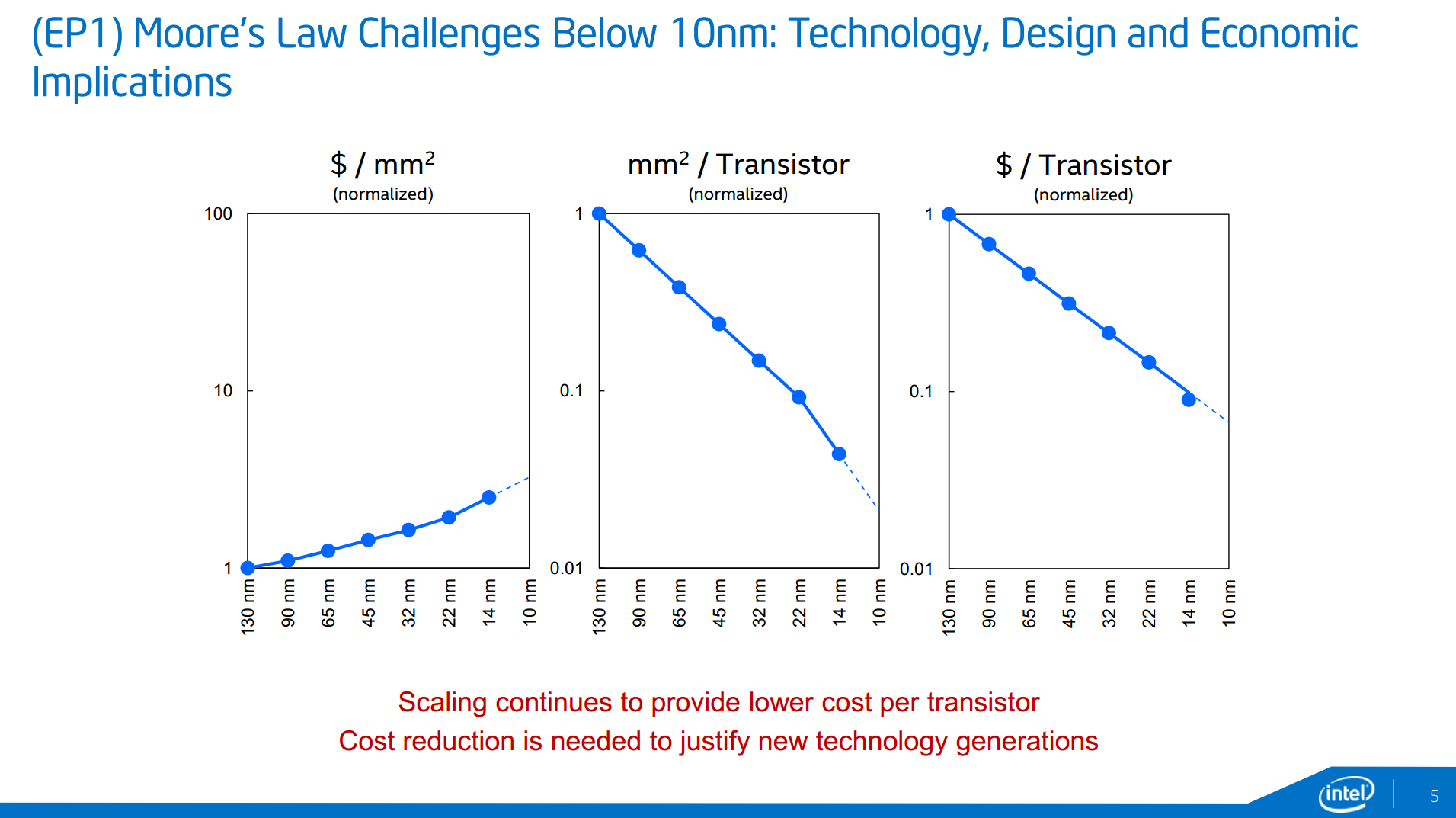
The fact that 14nm resulted in a better-than-the-trend drop in cost per transistor was explained as some internal smart reworking, making sure that certain areas of the dies require different masking and by optimizing the masking process, the cost can be reduced rather than relying on fewer general masks (but it is still a balance).
It was explained that while 10nm will have more masking steps than 14nm, and the delays that bogged down 14nm coming late to market will not be present at 10nm – or at least reduced. We were told that Intel has learned that the increase in development complexity of 14nm required more internal testing stages and masking implementations was a major reason for the delay, as well as requiring sufficient yields to go ahead with the launch. As a result, Intel is improving the efficiency testing at each stage and expediting the transfer of wafers with their testing protocols in order to avoid delays. Intel tells us that that their 10nm pilot lines are operating 50% faster than 14nm was as a result of these adjustments. So while the additional masking steps at 10nm which ultimately increases fixed costs, Intel is still quoting that their methods results in a reducing in terms of cost per transistor without needing a completely new patterning process. EUV lithography was discussed, but Intel seems to be hoping to avoid it until it is absolutely necessary, as EUV development so far has been slower to progress than expected.
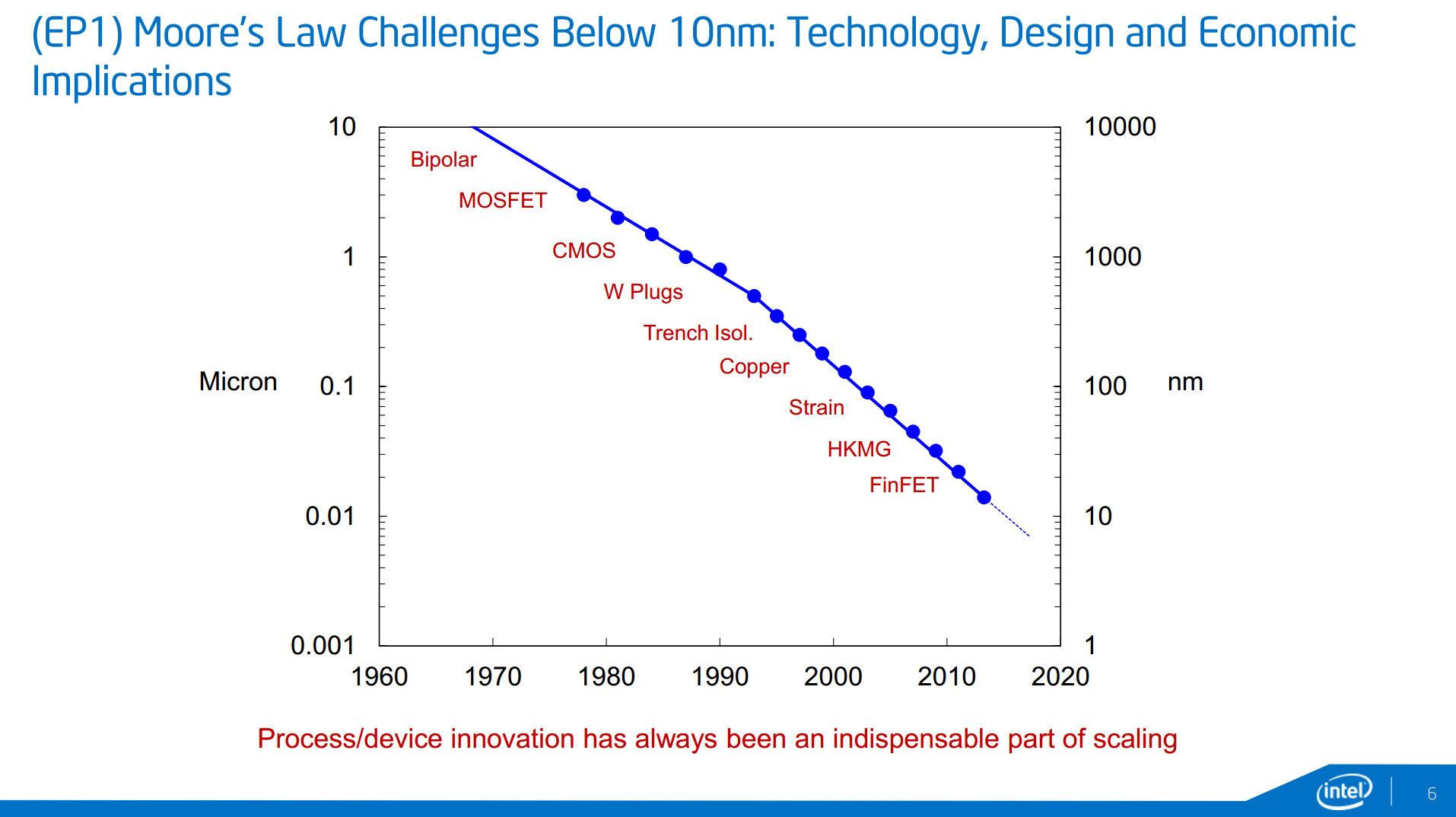
10 nm will come with innovation, and getting down to 7 nm will require new materials and processes which Intel wants to promote as a progressive integration between process development and the product design teams. New materials and device structures are key elements on that list, and while III-V materials were discussed in the ISSCC preview, no exact details were given.
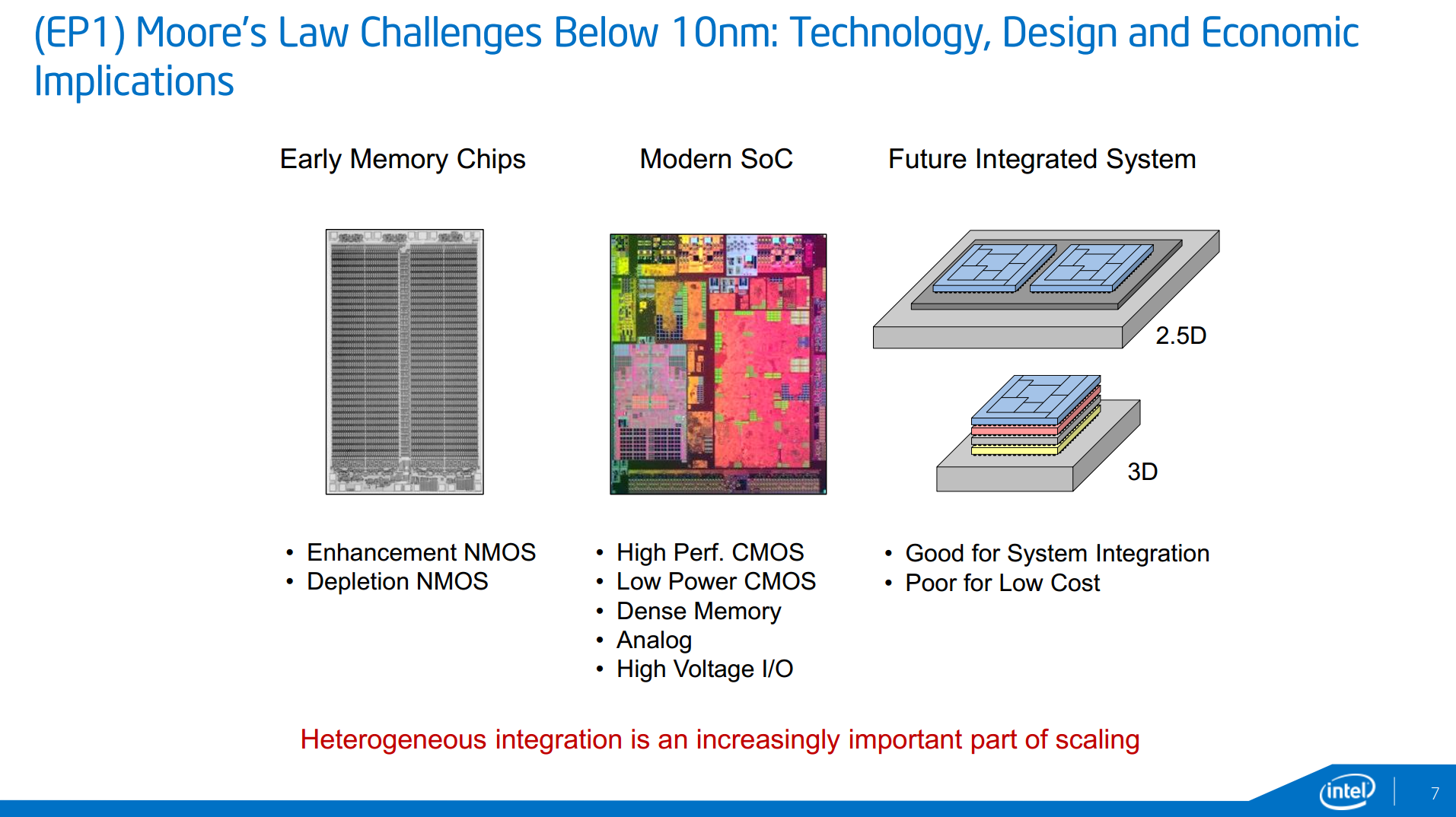
Along with addressing the general challenges in getting down to 7nm, Intel's research group is also looking to address future integrated systems, specifically 2.5D (separate dies on an interposer) and 3D (stacked dies). While 2.5D and 3D are not direct replacements for smaller manufacturing nodes - they just allow you to lay down more transistors at a higher cost - they are being examined as potential solutions for containing power consumption in certian situations (2.5D) or in building better size-limited integrated topologies (3D). Specifically, Intel is looking at scenarios where logic blocks using different fabrication methods are laid out in their own layers and stacked, rather than implemented on a single layer of a single die (think memory, digital logic, and analog communications on a single chip).
These kinds of configuration may appear in smartphones, tablets, or other devices that use highly-integrated chips where multiple types of fabrication would be necessary, and where manufacturers can charge the premium price necessary to cover the additional costs. We have discussed in the past how 2.5D and 3D configurations can improve performance, especially when it comes to memory density and graphics bandwidth, however the price increase (according to Intel) will result in that premium, even at high volume.
Reaping the Benefits of 14nm
Intel is highlighting a trio of papers at ISSCC regarding 14nm. One of the areas ripe for exploitation at 14nm is data transfer, especially transmitters. To that extent, Intel is showing a 14nm Tri-Gate CMOS serializer/deserializer transmitter capable of 16-40 Gbps, using both the NRZ (non-return zero) and PAM4 (Pulse-Amplitude Modulation with 4 levels) modes within a 0.03 millimeter squared die area.
![]()
Also on data transfer is a paper regarding the lowest power 10Gb/s serial link and the first complete serial link using 14nm Tri-Gate CMOS. Intel has working silicon at 14nm showing a 59mW power consumption within 0.065 millimeters squared die area that configures the committed data rate to provide the cleanest data response.

Perhaps the most exciting 14nm development is in the form of memory, with Intel describing in-house 84Mb SRAM design that uses the world’s smallest bitcell (0.050 micron squared). At 14nm it represents a doubling of the density at 14.5 Mb per square millimeter, but also provides substantially lower minimum voltage for a given frequency compared to the previous 22nm process. As shown in the graph in the slide, 0.6V is good for 1.5 GHz, but it can scale up to 3 GHz. It is also worth noting that the 14nm yield gradient is more conducive to lower voltage operation compared to the 22nm process. While it seems odd to promote an 84Mb (10.5 MB) design, Intel discussed that it can be scaled up over 100 Mb or more, making it a better solution for embedded devices rather than something like Crystal Well on desktop.

Still Developing on 22nm
While 14nm is great for density, lower voltage and lower power, other features on die are often produced at a looser resolution in order to ensure compatibility but it also offers a great research platform for testing new on-die features to be scaled down at a later date. To this extent, Intel Labs is also presenting a couple of papers about in-house test chips for new features.
The first test chip concerns data retention within register files. Depending on the external circumstances such as temperature and age, this adaptive and resilient domino register file testchip is designed to realign timing margins and detect errors as they occur and adjust the behavior in order to compensate. The logic that Intel is presenting is designed to also cater for die variation and voltage droop, making it more of a universal solution. On a higher level it sounds like the situation when NAND flash gets old and the onboard controller has to compensate for the voltage level margins.

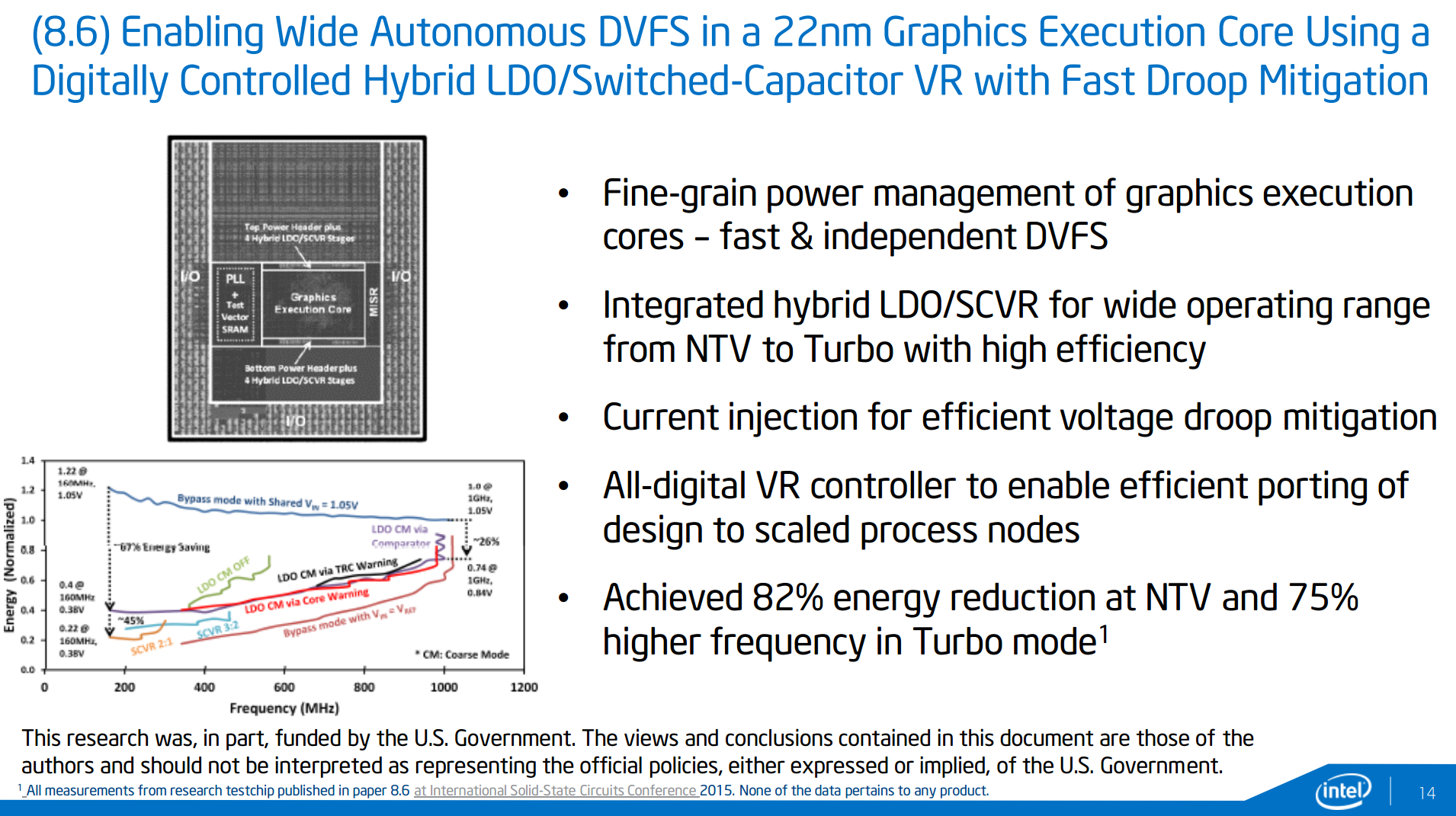
The second test-chip being described brings the situation down to Intel’s execution units in its graphics and dealing with fast, autonomous and independent dynamic voltage scaling. The use of a combined low-dropout regulator (LDO) for low voltages, such as at idle, and a switched capacitor voltage regulator (SCVR) for high voltages allow the appropriate current injection to deal with voltage droop as well as resulting in a large energy reduction. When applied, this should allow for either a power drop at the same frequency, or a higher frequency at the same voltage. Currently the numbers provided by Intel are all on internal silicon rather than anything in the wild, and will be examined at smaller nodes in due course.
Intel at ISSCC
ISSCC always throws out some interesting information about what is actually going on under the hood with the silicon we use almost every day, as we tend to think about it as a black box that slowly gets better over time. In reality, new features are fully researched and documented in order to be included in the next model, as well as trying to keep a balance of power usage and efficiency. On the CPU architecture side of the equation, we reported that Broadwell features needed to show a 2% performance or efficiency improvement for every 1% increase in power, making that advancement steeper than the 1:1 previously required. For all intents and purposes this means that if the same strategy is applied to 10nm and beyond, we are in for a very interesting time. It was interesting to hear about Intel speeding up on 10nm to avoid the delays occurred at 14nm, as well as thoughts regarding future technologies.
The papers Intel is presenting should be available via the ISSCC website as the presentations take place, along with a few others that pique our interest. This should get us ready for some interesting developments come Intel's Developer Forum later in the year.








55 Comments
View All Comments
nandnandnand - Sunday, February 22, 2015 - link
The grammar in this article is horrendous.Murloc - Sunday, February 22, 2015 - link
the paragraph after the second image has something wrong in it I think. The rest didn't seem wrong to me although it's complicated stuff so it's not exactly easy-flowing, not understanding much doesn't help of course :PKlug4Pres - Sunday, February 22, 2015 - link
I have to agree. My favourite sentence is:"Hot on the lips regarding Moore’s Law challenges comes down to future integrated systems, specifically 2.5D (separate dies on an interposer) and 3D (stacked dies)."
Klug4Pres - Sunday, February 22, 2015 - link
*Agree with nandnandnandDigitalFreak - Sunday, February 22, 2015 - link
I thought for a second that they hired Jason Mick from DailyTech to write this article...Frangelina - Sunday, February 22, 2015 - link
Be a happy unilinguist. Moreover, people from the math/non-verbal world, non native English speaker, are even more challenged.dishayu - Monday, February 23, 2015 - link
Dr. Ian Cutress is from the UK, as far as I remember.StevoLincolnite - Thursday, February 26, 2015 - link
I have been reading Anandtech for over a decade, overall I have a firm enough understanding of it all.This article left me confused.
I mean... Masking?
I know multiple terminology in this industry can mean the same thing, but I had assumed people in general meant "Patterning" in this context where Intel already does multi-patterning to boost yields, it's only natural to increase that as you drop down in lithography whilst keeping all else the same.
mkozakewich - Monday, February 23, 2015 - link
Hah, I thought the same thing. There was a sentence with a 'while' that just kind of ended without a counterpoint.Things seemed better after the first few paragraphs, though.
ingwe - Sunday, February 22, 2015 - link
Crazy stuff. I am curious to see how small things will actually get.