Kioxia Demonstrates RAID Offload Scheme for NVMe Drives
by Ganesh T S on August 12, 2024 2:30 PM EST
At FMS 2024, Kioxia had a proof-of-concept demonstration of their proposed a new RAID offload methodology for enterprise SSDs. The impetus for this is quite clear: as SSDs get faster in each generation, RAID arrays have a major problem of maintaining (and scaling up) performance. Even in cases where the RAID operations are handled by a dedicated RAID card, a simple write request in, say, a RAID 5 array would involve two reads and two writes to different drives. In cases where there is no hardware acceleration, the data from the reads needs to travel all the way back to the CPU and main memory for further processing before the writes can be done.
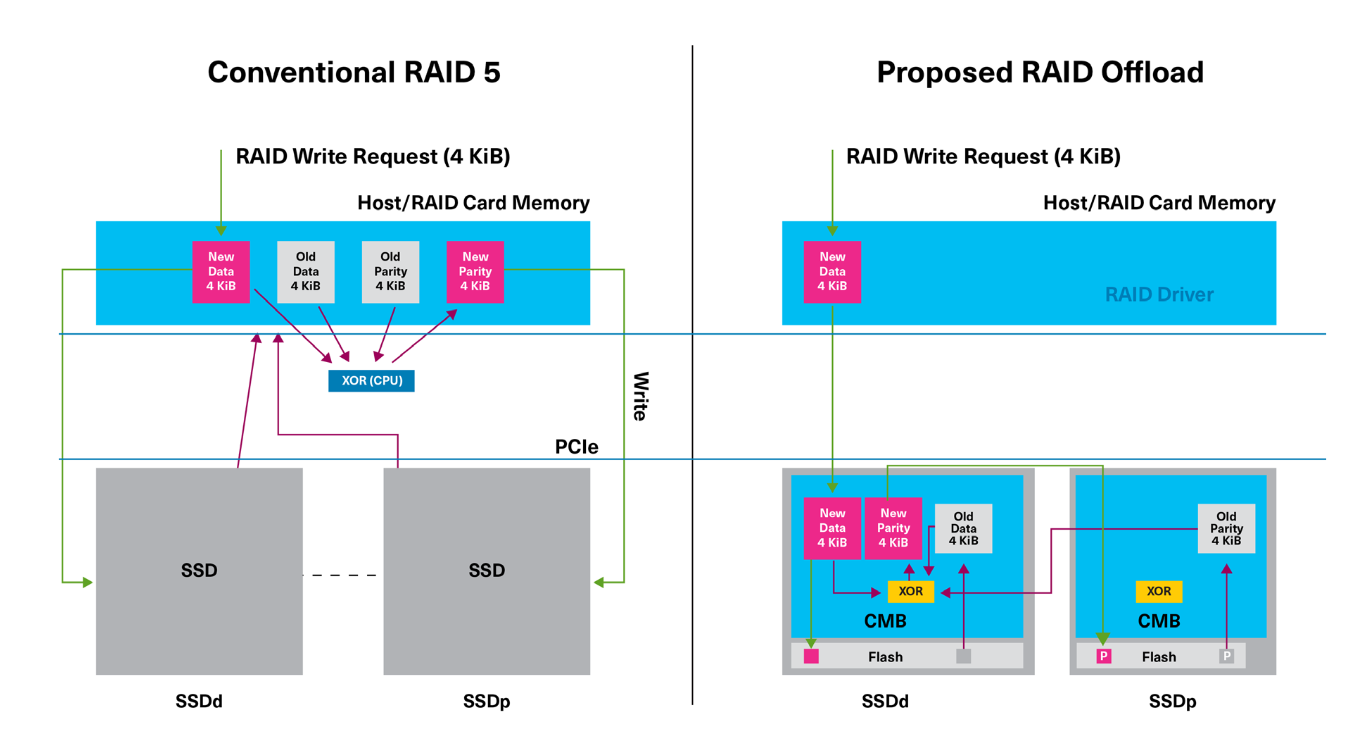
Kioxia has proposed the use of the PCIe direct memory access feature along with the SSD controller's controller memory buffer (CMB) to avoid the movement of data up to the CPU and back. The required parity computation is done by an accelerator block resident within the SSD controller.
In Kioxia's PoC implementation, the DMA engine can access the entire host address space (including the peer SSD's BAR-mapped CMB), allowing it to receive and transfer data as required from neighboring SSDs on the bus. Kioxia noted that their offload PoC saw close to 50% reduction in CPU utilization and upwards of 90% reduction in system DRAM utilization compared to software RAID done on the CPU. The proposed offload scheme can also handle scrubbing operations without taking up the host CPU cycles for the parity computation task.
Kioxia has already taken steps to contribute these features to the NVM Express working group. If accepted, the proposed offload scheme will be part of a standard that could become widely available across multiple SSD vendors.
Source: Kioxia








1 Comments
View All Comments
Kevin G - Monday, August 12, 2024 - link
While implied but never directly stated, the performance gains are on the COU of things with utilization reductions which in turn means more cycles toward other workloads. Not a bad thing but this doesn’t inherently equate to faster drive speeds. In fact these might be slightly less due to parity overhead transfers from drive to drive.This is a novel way of scaling array performance in the era of high speed NVMe. If the controller is already doing some parity calculation on blocks for its own integrity, being able to simply shuffle that result result off to another drive is efficient. The way traditional RAID5 works would still require some MUX of multiple input blocks to be stored but that effectively boils down to IO parsing. This would have a nominal impact on power consumption this way too.
There are a couple of details that’s need to be worked out for mass enterprise support for this technology. The first is good interoperability which goes beyond specific vendor but mixing models and even firmware. In other words it’d be ideal for say Kioxia and Solidigm to work together on this RAID acceleration so that enterprises wouldn’t have to go to a single vendor for a reaplcement disk. Vendor lock-in is just bad and submitting this as a standard to the NVMe spec is a good move to prevent that. There are details about how a rebuild happens that just needs to be disclosed. Similarly is the capability to expand or even contract an array safely. The last issue is that hardware RAID has seen a decline due to its past as a vendor lock-in technology. This was at the controller level and not the drive level. What has risen since then have been software defined solutions like ZFS which focus on data integrity. Given how ZFS does the parity computation first before writing across the drives (and then invalidating old blocks for a data update), this new accelerated technique inherently may be incompatible with ZFS’s integrity algorithms. At the very least some significant rework would need to be done.