TACC Frontera: Targeting 210W Next-Gen Xeons and Extreme Performance
by Ian Cutress on November 12, 2018 8:00 AM EST- Posted in
- CPUs
- Intel
- HPC
- Enterprise CPUs
- TACC
- Frontera
- Supercomputing 18
The Frontera supercomputer is the next generation high performance machine set to debut at the Texas Advanced Computing Center (TACC) in 2019. As part of Intel’s HPC Forum, being held just before the annual Supercomputing conference, a number of disclosures about the design of Frontera (Spanish for ‘Frontier’) were made. One of which is certainly worth highlighting: this is not a supercomputer that is going to worry about performance per watt – this is all about the peak performance.
Supercomputer Procurement Goals
When building and investing in a supercomputer, there are several different limits to be mindful of: total cost of ownership, physical space, cooling capacity, workload demands (memory intensive vs compute intensive), administration challenges, user base, storage, and expected life time of the installation. Boiled down, most high performance computer builds focus on performance per watt scaling for performance. This is why we often see single socket and dual socket systems with processors found in the middle of what the processor manufacturer offers. There are plenty of supercomputers deployed globally that are built upon Xeon E5-2640 type processors, or more recently, mid-placed Xeon Gold processors.
Don Stanzione, the Executive Director at TACC, went into some detail about the focus of Frontera, its next generation supercomputer cluster it intends to deploy in 2019. TACC already has a number of deployments, such as Stampede (6400 nodes, Xeon CPU + Xeon Phi + Omnipath), Lonestar (12-core Xeon + some K40), and Maverick (132 nodes, 10-core Xeon + K40). Frontera is going to be the new TACC flagship compute system, involving high performance Xeons, Mellanox interconnect, liquid and oil cooling, and optimized storage systems.
High Power Next-Gen Xeons
At the heart of Frontera, it will be solely Xeon based. We were told that the goal for the system is to provide 35-40 PetaFLOPS, with the exact number dependent on what frequencies Intel will use in its next generation (read Cascade Lake) Xeons. There will be a few NVIDIA nodes for single precision computing, but we were told that the users for Frontera are not that interested about learning new computing paradigms to take advantage of the computing resources: what they want is more of the same, but just faster. The best way to do this, we were told, was to keep the system architecture the same (AVX-512 based compute processors), but more cores and higher frequencies with similar node-to-cluster connectivity. As a result, Frontera is built with the high TDP Xeon processors in mind, the 205-210W parts, rather than the 145W parts.
In this situation, users can develop programs with less node-to-node communication, and it should offer a faster speedup of legacy code without refactoring code. The easiest way to improve performance is more frequency, regardless of efficiency - adding more CPUs and more nodes is a complex way to improve performance, and the goal of Frontera is to make this 'easy'.

Because of the high thermal requirements, water cooling will be used for the majority of the nodes. Because the nodes are coming from DellEMC, and DellEMC works with CoolIT, the liquid cooling will be from CoolIT. Some of the nodes will use oil immersion techniques, from GRC, although it wasn’t stated what sort of nodes this will be. No mention was made if the liquid cooling will be warm liquid cooling, but we were told that this scheme is put in place not because it is the most power efficient, but because it gives the userbase the best speedup for the least amount of work.

Other information about the deployment includes the interconnect, using Mellanox HDR and HDR-100, using a Fat Tree topology and 200 Gb/s links between switches. Storage will be split depending on the user and the workload: there will be four different storage environments, three based on general storage, and one on very fast connectivity using peak IO as the main metric. Users interested in using the peak IO storage will need to be pre-approved. The storage implementation will be developed by DataDirect Networks, who has previous relationships with TACC, and the global storage should be north of 50+ PB with around 3PB of NAND Flash and around 1.5TB/sec of storage connectivity.
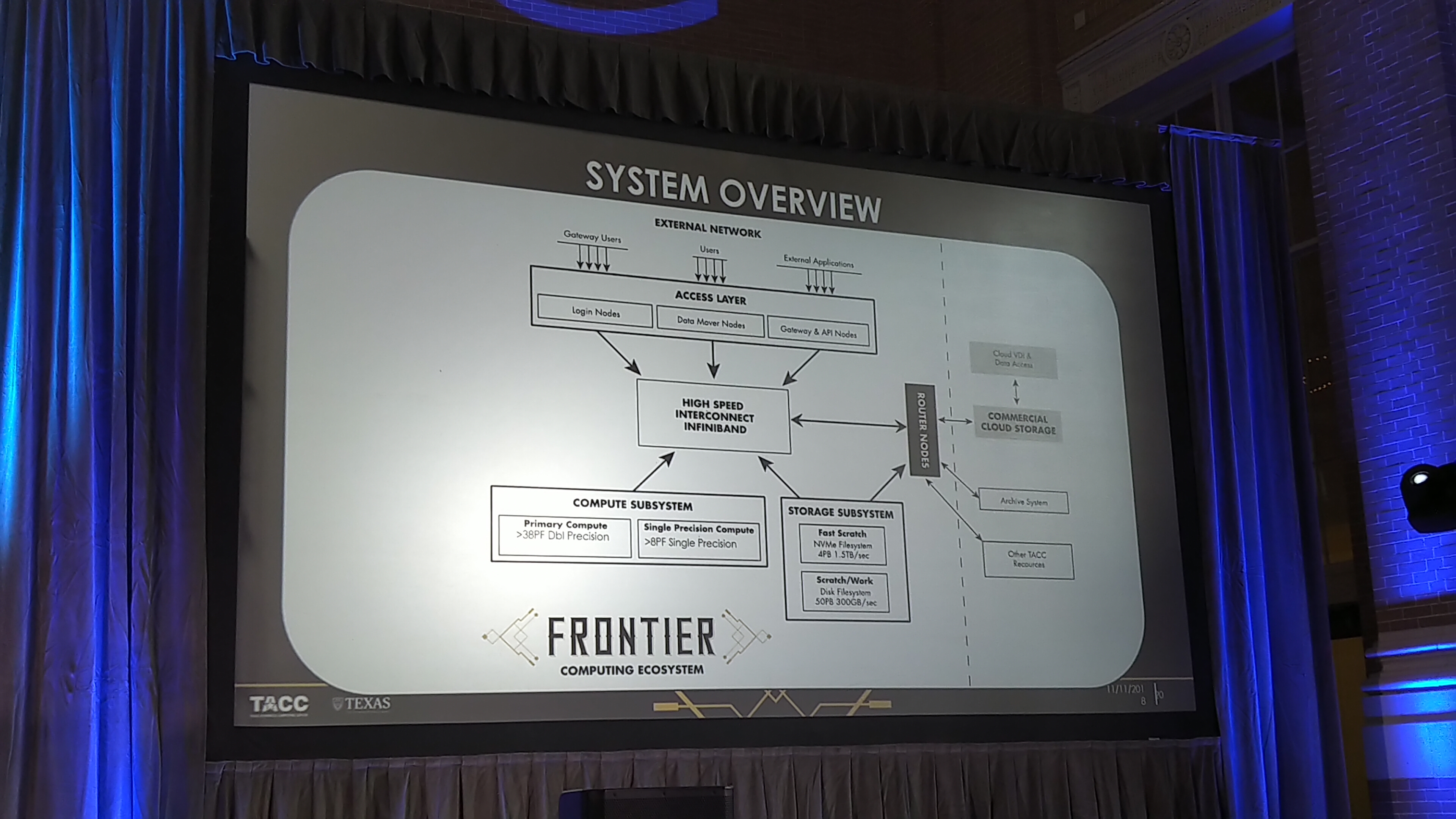
The full Frontera will have above 8000 compute nodes, and have a peak power around 6 MW, which is well within the capability of TACC’s current infrastructure. Each rack will be around 65 KW, which comes out at around 100 racks in total. Cores per rack were not disclosed, although 65 KW/rack and 210W/CPU would mean a maximum of 310 CPUs, although that doesn’t give any overhead or include the storage. If you wanted to multiply out all the data, and assume that every CPU is the 28-core versions, we’re looking at an upper bound of 850,000 cores, with the actual number being much lower due to the infrastructure. The supercomputer will use part solar power, and around 1/3 of the power from wind power credits and wind power production.
Frontera is also being planned with a second phase deployment in mind in 2024-2025. TACC will deploy a number of development systems, including FPGA systems, quantum simulators, Tensor core systems, and even Optane deployed next-gen Xeon systems. The idea is that these systems will be available for development work and hopefully direct the future growth of Frontera. Phase 2 is expected to be a factor 10x faster for compute.






Frontera will enter production in the summer of 2019, and is funded by a $60m grant from the National Science Foundation. This is compared to the $30m grant used for the Xeon-Phi based Stampede2 system that currently runs at 18 PetaFLOPs.








9 Comments
View All Comments
essemzed - Monday, November 12, 2018 - link
I'm relieved they didn't call it "barrera"...IGTrading - Monday, November 12, 2018 - link
I guess they are powerless in the face of the Intel frontier and unable to design a better and more efficient solution with #AMD EPYC 2 .Oh well, it is "good" that national funds in millions go to further support the de-facto Intel monopoly on the x86 server market ;)
Somebody, somewhere was "smart" and "honest" to do this and his / their direct or in-direct profit and advantages had nothing to do with it ...
HStewart - Monday, November 12, 2018 - link
"de-facto Intel monopoly on the x86 server market "I am sorry I trying to resist in these stupid discussions - but it not de-facto but instead perceived. I guess some people believe the more it said to others the more they believe it. It not a monopoly, since you have a choice - but telling others it is monopoly when the fact that AMD exists does not make it one is just wrong and one of primary reasons why some people will never even purchase AMD.
It just really wrong there every time there is an article about Intel or even in this case that people put in garbage about Intel - but if anyone makes any positive comments about Intel or reply to message that distracts for actually article is about.
I never heard of this this system but to have 8000 computer sounds like it system is very scalable. But away above most common users and gamers.
sa666666 - Monday, November 12, 2018 - link
Truth hurts, doesn't it. You mad bro?Lord of the Bored - Monday, November 12, 2018 - link
"I never heard of this this system but to have 8000 computer sounds like it system is very scalable. But away above most common users and gamers."Supercomputers: not for gamers!
IGTrading - Tuesday, November 13, 2018 - link
I think you can be one of these two : either too young and inexperienced to know what you're talking about or you have a vested interest in defending a horrible criminal organization like Intel, who's offices were raided by the Police & authorities in more than 5 countries on 3 different continents.During my 22 years of working in this industry, I often came across agreements like Intel's "special" discounts. These are mafia-like protocols that go beyond 4% discount for quantities over 2K pcs, 6% for over 4k pcs and 11% for over 6k pcs.
The "special" Intel agreements state things like: 7~9~16% discount levels IF the OEM or distibutor would manage its AMD-based sales around and under the 9% mark (out of total sales).
Therefore Intel says : "if you promise not to sell AMD in more than 9% of your products , we will increase the discounts we're offering" ... "even doubling them" .
Basically, if the OEM "dares" to sell AMD in more than 9% of its products, they will lose 50% of the discounts Intel is diving them for the rest of their products (which is 91% of total sales) .
What company would risk losing half of all their discounts on 91% of their products ?
Yes mate, there is a "choice" but are they free to make it ? Is it a free choice, or does it come with a serious financial hit ?
And when most OEMs are under such control under Intel, you wonder why there were ZERO design wins for AMD Mullins , which was between 50% to 200% faster than Intel's Atom while consuming less ?!
If Atom was so good, why did Intel lose 4 billion USD and never made a single dollar of profit out of Atom tablets ? ;) Why wouldn't they stop the loss at the first billion ? Why not at the 3rd billion lost ? (Intel lost 1 billion USD per year on Atom)
Because by force-feeding Atom to the market, Intel deprived AMD of the sales, revenues, profits and positive image it would have gotten from having a success on the x86 tablet market.
The same happens in the server market and the notebook laptop market.
This is re-confirmed today , this quarter by the falling sales on the PC market , caused by the Intel shortages.
If they would be free, OEMs would sell AMD instead of Intel. The end customer needs a good PC. Even if they specifically want Intel, all projects have deadlines and you will buy whatever is available, to meet those deadlines.
But OEM prefer to lose sales, than to go above that agreed 9% of AMD-based product percentage, and risk losing Intel's "special" discounts on the rest of 91% of their sales.
NikosD - Saturday, November 17, 2018 - link
This is by far the best inside comment I have read for a long time in this decades old war between Intel and AMD.Gideon - Monday, November 12, 2018 - link
This is relatively old news. From this August article:https://www.nextplatform.com/2018/08/29/cascade-la...
Stanzione says TACC made the decision to go with the Cascade Lake SKUs that have the higher clock rates and they expect most codes will run significantly faster. His team took a close look at other processor options, including the 7 nanometer AMD “Rome” Epyc “chips coming next year, which he says were a closer frontrunner in their decision-making process. “We took a look at AMD Epyc, both Naples and certainly Rome, but with the combination of price, schedules, and performance, we felt like Cascade Lake was the way to get the best value right now. Our codes were just a little better for the time we needed this system but Rome is a promising architecture and we expect it is going to be a very good chip,” Stanzione explained.
Rudde - Monday, November 12, 2018 - link
With 2 sockets per node and 8000 nodes using 28 core cpus the total core count is 448 000. If each cpu draws 210W, the total power consumption is 3.36MW from the cpus alone.Now if we assume that the fpus are similar to Skylake (32 dp flops / clock) and a total of 38 petaflops we get a frequency of 2.65GHz (assume 40petaflops and the frequency jumps to 2.79GHz). For comparision, Intel Xeon 8160 has a fpu frequency of 2GHz. The Cascade lake processor is claimed to have 25%-30% higher frequency. 2.65/2≈1.33.
This is how far I'll go with back of napkin calculations and speculation.