896 Xeon Cores in One PC: Microsoft’s New x86 DataCenter Class Machines Running Windows
by Ian Cutress on October 26, 2018 11:00 AM EST- Posted in
- CPUs
- Windows
- Microsoft
- Enterprise CPUs
- Azure

This week Microsoft released a new blog dedicated to the Windows Kernel internals. The purpose of the blog is to dive into the Kernel across a variety of architectures and delve into the elements, such as the evolution of the kernel, the components, the organization, and in this post, the focus was on the scheduler. The goal is to develop the blog over the next few months with insights into what goes on behind the scenes, and the reasons why it does what it does. However, we got a sneak peek into a big system that Microsoft looks like it is working on.
For those that want to read the blog, it’s really good. Take a look here:
https://techcommunity.microsoft.com/t5/Windows-Kernel-Internals/One-Windows-Kernel/ba-p/267142
When discussing the scalability of Windows, the author Hari Pulapaka, Lead Program Manager in the Windows Core Kernel Platform, showcases a screenshot of Task Manager from what he describes as a ‘pre-release Windows DataCenter class machine’ running Windows. Here’s the image:
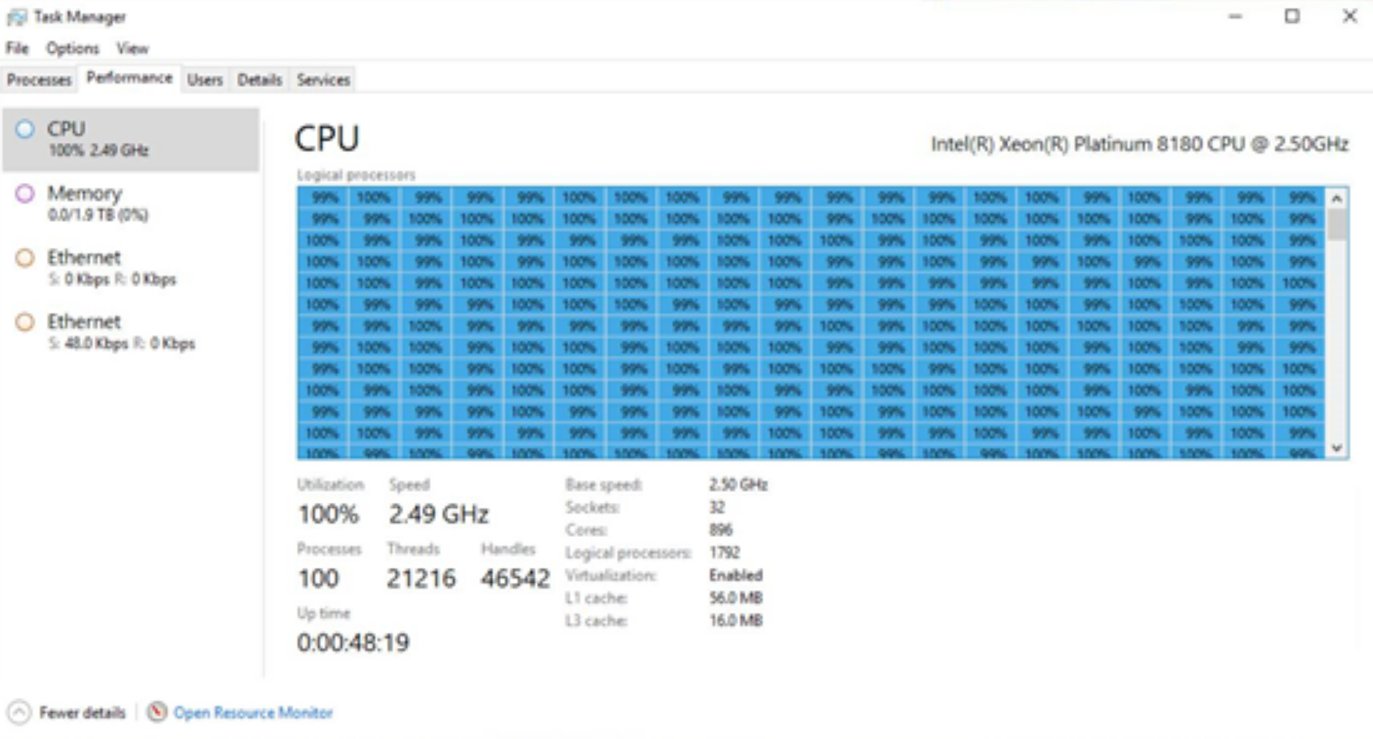
Click to zoom. Unfortunately the original image is low resolution
If you weren’t amazed by the number of threads in task manager, you might notice that on the side there’s a scroll bar. That’s right: 896 cores means 1792 threads when hyperthreading is enabled, which is too much for task manager to show at once, and this new type of ‘DataCenter class machine’ looks like it has access to them all. But what are we really seeing here, aside from every single thread loaded at 100%?
So to start, the CPU listed is a Xeon Platinum 8180, Intel’s highest core count, highest performing Xeon Scalable ‘Skylake-SP’ processor. It has 28 cores and 56 threads, and by math we get a 32 socket system. In fact in the bumf below the threads all running at 100%, it literally says ‘Sockets: 32’. So this is 32 full 28 core processors all acting together under one version of Windows. Again, the question is how?
Normally, Intel only rates Xeon Platinum processors for up to 8 sockets. It does this by using three QPI links per processor to form a dual-box configuration. The Xeon Gold 6100 range does up to four sockets with three QPI links, ensuring each processor is linked to each other processor, and then the rest of the range does single socket or dual socket.
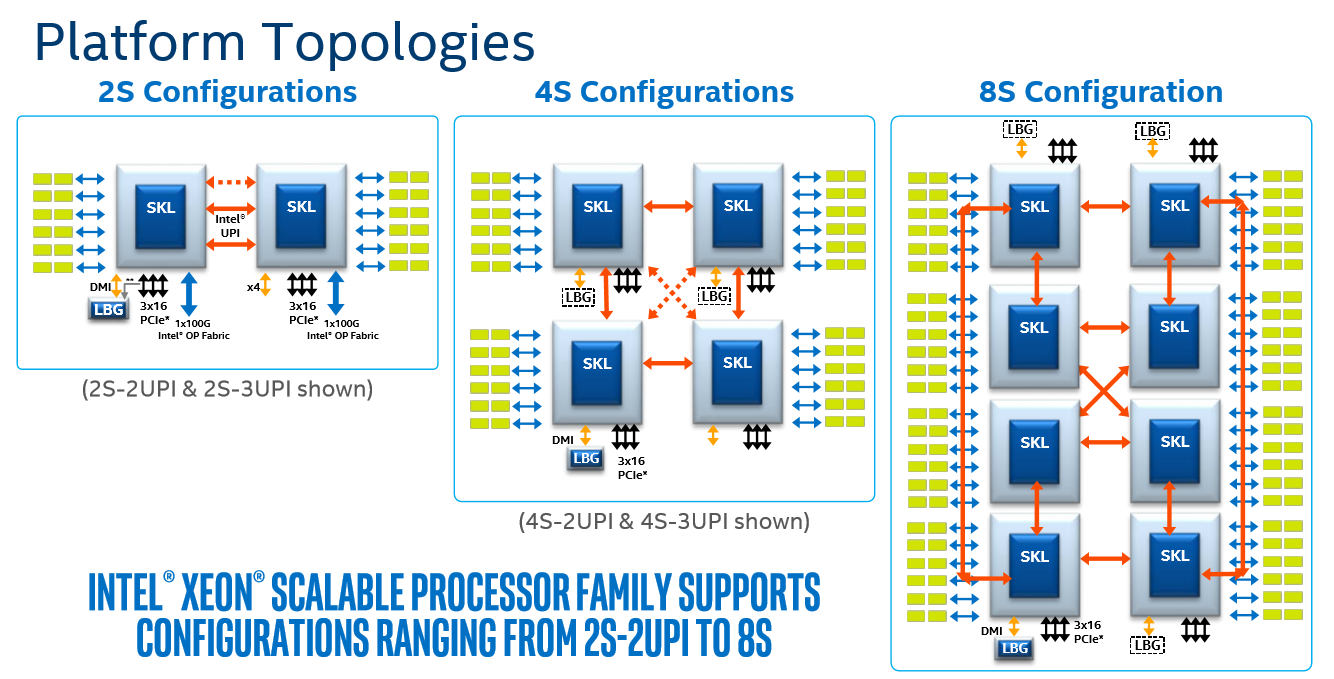
What Intel doesn’t mention is that with an appropriate fabric connecting them, system builders and OEMs can chain together several 4-socket or 8-socket systems into a single, many-socket interface. Aside from the fabric to be used and the messaging, there are other factors in play here, such as latency and memory architecture, which are already present in 2-8 socket platforms but get substantially increased going beyond eight sockets. If one processor needs memory that is two fabric hops and a processor hop is away, to a certain extent having that data in a local SDD might be quicker.
As for the fabric: I’m actually going to use an analogy here. AMD’s EPYC platform goes up to two sockets, but for the interconnect between sockets, it uses 64 PCIe lanes from each processor to host AMD’s Infinity Fabric protocol to act as links, and has the benefit of the combined bandwidth of 128 PCIe lanes. If EPYC had 256 PCIe lanes for example, or cut the number of PCIe lanes down to 32 per link, then we could end up with EPYC servers with more than two sockets built on Infinity Fabric. With Intel CPUs, we’re still using the PCIe lanes, but we’re doing it in one of three ways: control over Omni-Path using PCIe, control over Infiniband using PCIe, or control using custom FPGAs, again over PCIe. This is essentially how modern supercomputers are run, albeit not as one unified system.
Unfortunately this is where we go out of my depth. When I spoke to a large server OEM last year, they said quad socket and eight socket systems are becoming rarer and rarer as each CPU by itself has more cores the need for systems that big just doesn't exist anymore. Back in the days pre-Nehalem, the big eight socket 32-core servers were all the rage, but today not so much, and unless a company is willing to spend $250k+ (before support contracts or DRAM/NAND) on a single 8-socket system, it’s reserved for the big players in town. Today, those are the cloud providers.
In order to get 32 sockets, we’re likely seeing eight quad-socket systems connected in this way in one big blade infrastructure. It likely takes up half a rack, of not a whole one, and your guess is as good as mine on the price, or power consumption. In our screenshot above it does say ‘Virtualization: Enabled’, and given that this is Microsoft we’re talking about, this might be one of their internal planned Azure systems that is either rented to defence-like contractors or partitioned off in instances to others.
I’ve tried reaching out to Hari to get more information on the system this is, and will report back if we get anything. Microsoft may make an official announcement if these large 32-socket systems are going to be 'widespread' (meant in the leanest sense) offerings on Azure.
Note: DataCenter is stylized with a capital C as quoted through Microsoft's blog post.








56 Comments
View All Comments
HStewart - Friday, October 26, 2018 - link
My guess is this is joint venture between Microsoft and Intel. Intel called the new Xeon's scalable for a reason and I believe this system has new chipset that allows it to scalable to from 8 to 16 to 32 cpus's and maybe any more.Intel has 8 cpu systems for over a decade - my biggest question since the occurance of multi-core cpu's is what is difference between 8 single core box and 8-core cpu in performance.
Of course there is some physical limitations of budding say using Zen architecture system with 896 process system with 112 8-core zen's
I think Intel / Microsoft have found a way to interconnects scalable and this comes interesting thought on value of have more cores on cpu. Especially if system was designed to be pluggable and if one of cpu's failed than it does not bring entire system down.
name99 - Friday, October 26, 2018 - link
What EXACTLY is promised here? A 32-element cluster of 28 core elements, or even a 4-element cluster of 8*28 core elements is no big deal; a cluster OS is doubtless useful for MS, but no great breakthrough. So is the claim that this is a SINGLE COHERENT address space?As cekim says below, why? What does coherency buy you here? And if it's not coherent, then what's new? Is the point that they managed to get massive-scale coherency without a dramatic cost in latency and extra hardware (directories and suchlike)?
HStewart - Friday, October 26, 2018 - link
what is then the difference of 32 core single cpu and dual 16 core system? In single OS we usued have to run multiple CPU but now we have multiple core system which is great for laptop but when we talking about servers - why not have 32 cpus in the boxed also. In that world core could is basically cores per cpu multiple socketsmode_13h - Friday, October 26, 2018 - link
You're conveniently abstracting away all of the practical details that would answer your question.peevee - Monday, October 29, 2018 - link
"So is the claim that this is a SINGLE COHERENT address space?"Almost certainly.
"As cekim says below, why? What does coherency buy you here?"
Nothing particularly good. A temptation to use SMP or even 2-node-optimized NUMA software, only to discover that it does not scale beyond 16-32 threads.
cekim - Friday, October 26, 2018 - link
Welcome to 20 years ago with SSI, SKMD, MOSIX, etc... This avenue of architecture has a trail of bodies on it so far. Just no compelling improvement over other variations of task migration, load sharing, MPI, etc... thus far demonstrated to justify the complexity in 99.99999999999% of use cases. Windows has such a solid track record on scheduling and stability so far, I’d be sure to sign up for more pain the first chance I got... /sarcasmHStewart - Friday, October 26, 2018 - link
One thing different, is that a single one of these 896 cores in this beast is more power than main frame computers from 20 years ago and now you have 896 of these in at least 1/10 the size.cekim - Friday, October 26, 2018 - link
That’s not different than single system image... just higher density. Companies like cray, SGI, Fujitsu etc... have been taking any processor they can get their hands on and connecting them up to high speed low latency fabrics and providing a single system image view of such machines from the operator level. When cray/sgi used alphas, mips opterons and xeons with 1-N cores for this. Once Beowulf showed up things migrated that way to using commodity or leading edge but still Off-the-shelf networks of independent nodes with a central director node....This is a pretty well worn path at this point. The question is whether MSFT can provide a compelling licensing option and make it actually perform?
HStewart - Friday, October 26, 2018 - link
One difference possibly could be memory usage depending on how the bus is mademode_13h - Friday, October 26, 2018 - link
Um, no. Memory usage must be local to each blade, or else it will perform like garbage. Power efficiency would be much worse, as well.