Hot Chips 2018: Tachyum Prodigy CPU Live Blog
by Dr. Ian Cutress on August 21, 2018 5:55 PM EST- Posted in
- CPUs
- Hot Chips
- Trade Shows
- SoCs
- Enterprise CPUs
- Live Blog
- Tachyum
- Mesh
- Ring

05:55PM EDT - One of the more interesting talks is from Tachyum, who have a deep presentation about their new hyperscale Prodigy processors with up to 64 cores and eight channel memory. Tachyum is headed up by one of the original co-Founders of SandForce and Wave Computing. The talk is set to start at 3pm PT / 10pm UTC.

06:01PM EDT - Trying to give the best of CPU GPU TPU

06:01PM EDT - Prodigy is a server/AI/supercomputer chip for hyperscale datacenters
06:01PM EDT - Is programmable and optimized
06:02PM EDT - AI based on spiking model requires other hardware
06:02PM EDT - Not all AI is neural networks
06:02PM EDT - Tape out in 2019

06:02PM EDT - One die with three different versions
06:03PM EDT - Different variants for different markets
06:03PM EDT - T864 = 64 cores and 8 DDR4/5 controllers, 72 PCIe 5.0, 2x400G internet on single piece of silicon
06:03PM EDT - Each core will be faster than Intel Xeon

06:03PM EDT - Single threaded performance on Spec INT/FP better than Xeon
06:04PM EDT - 2TF performance per core
06:04PM EDT - Better perf than Volta chip wide
06:04PM EDT - 180W at 4 GHz
06:04PM EDT - 7nm, 12 metal layers, 0.8V, 290 mm2
06:05PM EDT - Data wires are small to reduce power
06:05PM EDT - Smaller than ARM
06:05PM EDT - Using standard cells and memories
06:05PM EDT - In order design - out of order execution with compiler
06:05PM EDT - Accepts C/C++/Fortran
06:05PM EDT - Programming model is CPU-like
06:06PM EDT - 32 x INT64 registers
06:06PM EDT - 32 vector registers 256/128 bits

06:06PM EDT - Sorry pictures have stopped
06:06PM EDT - maybe not
06:06PM EDT - ILP based on bundling
06:07PM EDT - 2 load + 2 multiply-add + 1 store + 1 address increment + 1 compre + 1 branch per clock
06:07PM EDT - 1.72 instructions per cycle normal
06:07PM EDT - based on bundle size from compiler
06:07PM EDT - 2.6 instructions/bundle on average
06:07PM EDT - 8-RISC-style micro-ops per cycle
06:08PM EDT - Itanium was stalled 50% of the time due to dynamic scheduling. Normal OoO core is about 15%. Due to our simulator, we achieve less than 20% stall
06:08PM EDT - Can do OoO and speculation in software without expensive hardware
06:08PM EDT - Changing the perf/$ and perf/W equation
06:09PM EDT - Linux and FreeBSD ported in 2019
06:09PM EDT - Device drivers, boot-loaded and Java JIT

06:09PM EDT - Replace parts of GCC to enable Prodigy core
06:09PM EDT - Working so critical applications work day one
06:10PM EDT - Learning from Arm entering the hyperscale space - took over 12 months and $100m to compile and port to Arm
06:10PM EDT - For a startup that would be problem
06:10PM EDT - Allow customers to use x86 binary through QEMU emulator
06:11PM EDT - allows for shorter deployment time
06:11PM EDT - Existing binaries supported via emulators
06:11PM EDT - Use service providers in Europe to port existing applications
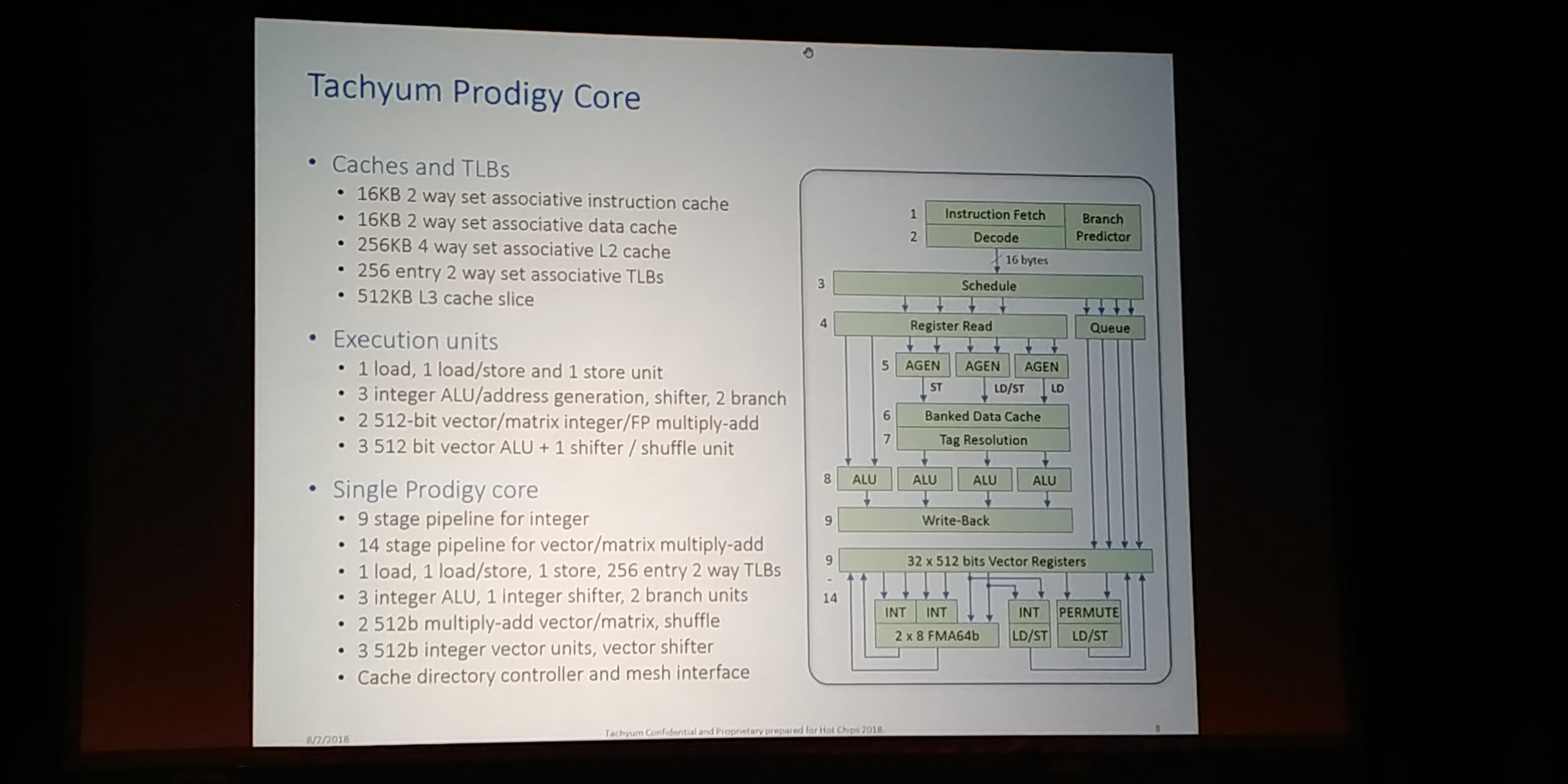
06:12PM EDT - The core - 8 micro-ops decode and dispatch per clock (16 bytes per op)
06:12PM EDT - 1 store, 1 load, 1 load/store unit
06:12PM EDT - 32 x 512-bit vector registers

06:12PM EDT - Conventional front end
06:12PM EDT - Simple branch predictor works sufficiently well with compiler
06:13PM EDT - Machine can execute 1-4 words per clock, each word with 1-2 ops
06:13PM EDT - Instruction Execution looks like in-order, but can slide instructions on cache misses

06:14PM EDT - 9-stage pipeline due to no register renaming required
06:14PM EDT - Supports 64B/clock per memory op into L1

06:14PM EDT - Private 512KB L2 cache
06:14PM EDT - Spill and fill with data cache and L2 cache
06:15PM EDT - L3 distributed cache is same latency as L2
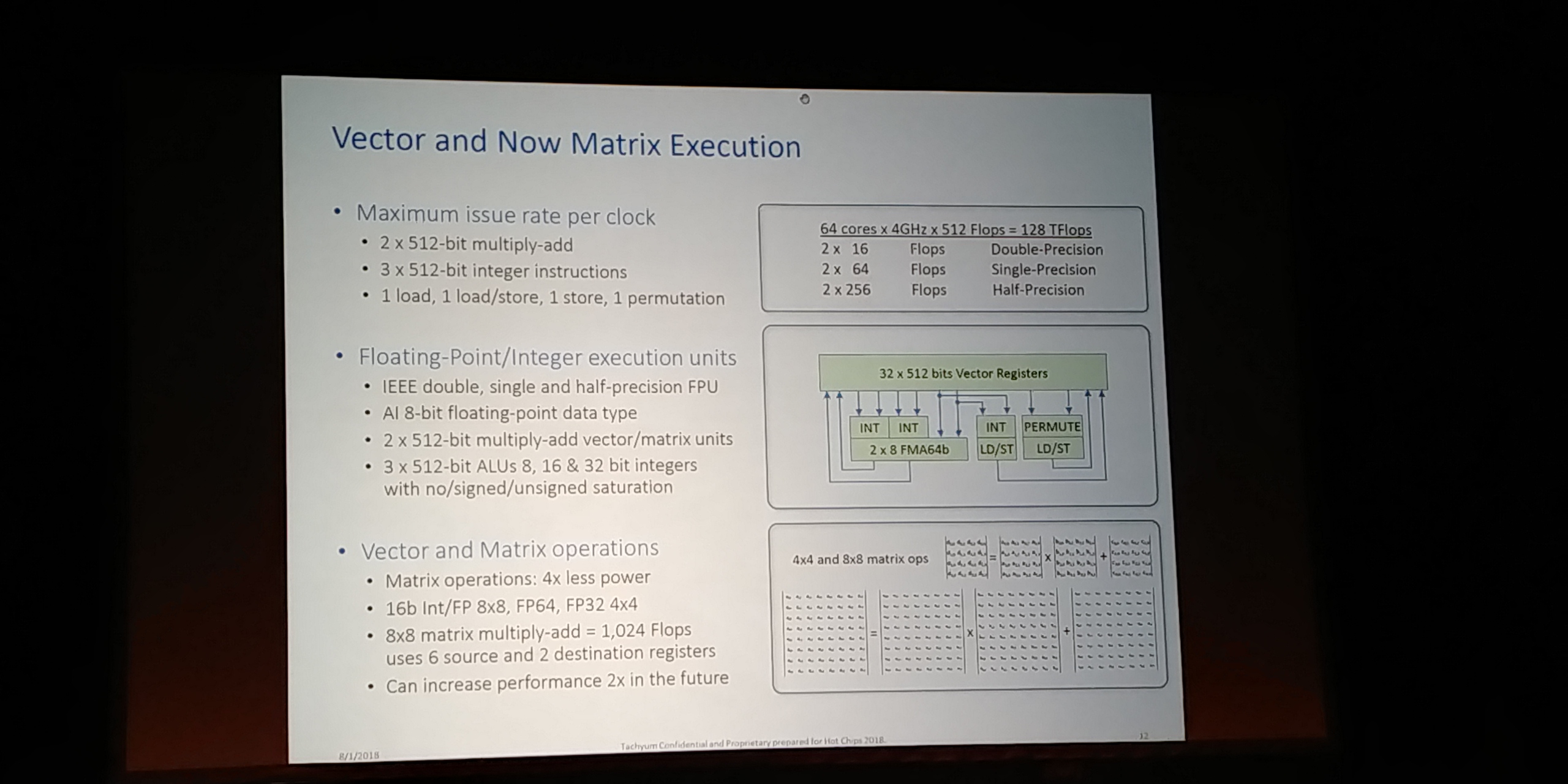
06:15PM EDT - Supports FP16 and INT8
06:15PM EDT - 2x512-bit MAC or 3x512-bit int per clcok
06:16PM EDT - Standard mesh with the cores, 8x8
06:16PM EDT - It also has an IO ring
06:16PM EDT - for networking applications, lower latency for far memory access

06:16PM EDT - important for no packet loss and reduces congestion
06:16PM EDT - 32 bytes per clock per direction I/O to DRAM
06:17PM EDT - 2 x HBM3 controllers and 8 x DDR controllers
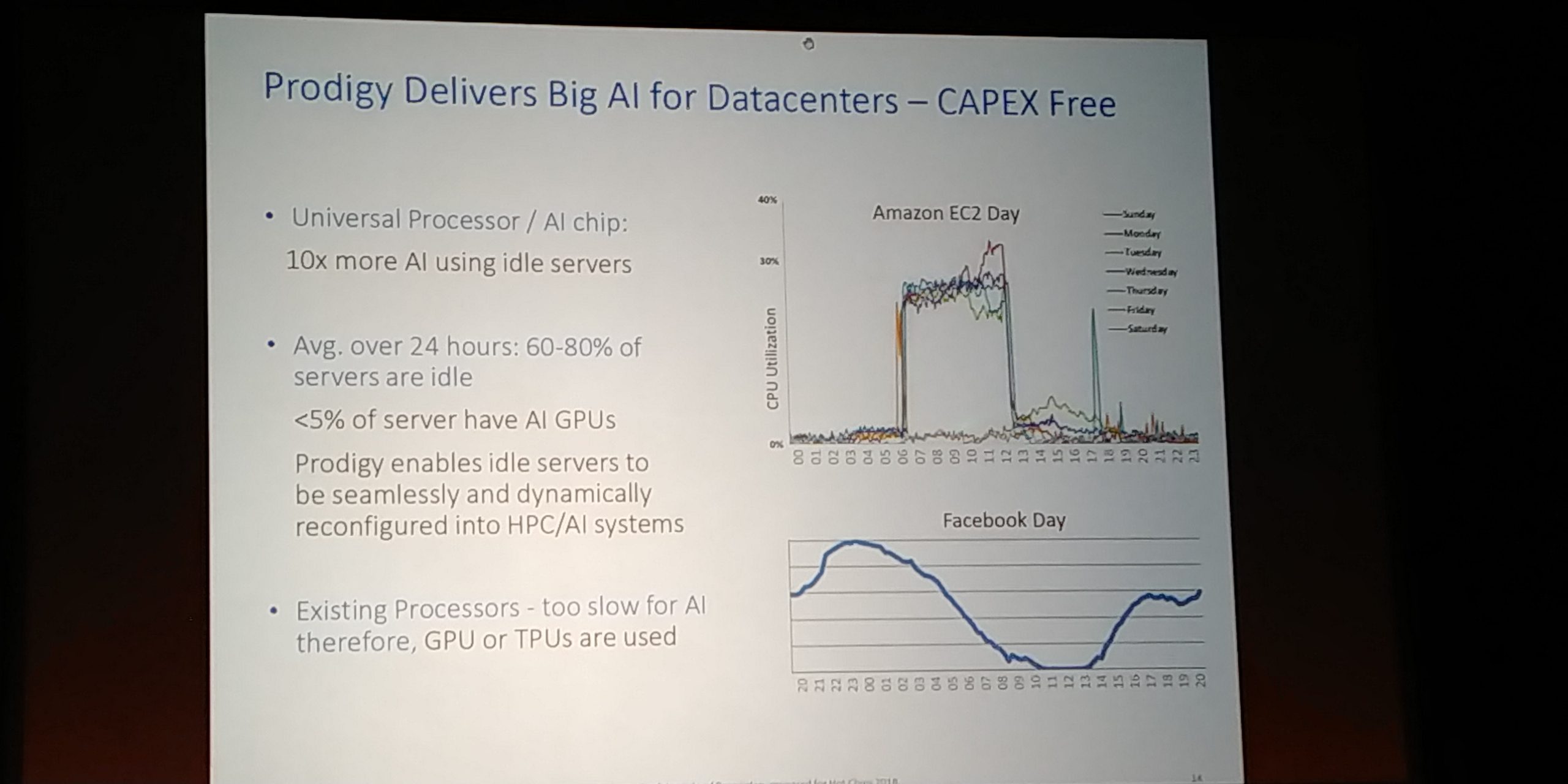
06:17PM EDT - Average utilization on Amazon EC is 30%. Facebook average utilization is 40%
06:18PM EDT - 60-70% idle. With an AI chip, you can train / inference when idle with chips that are capable
06:18PM EDT - Our chips you can run servers and then AI when idle
06:18PM EDT - access to 20x AI
06:18PM EDT - don't need different hardware

06:19PM EDT - In a Facebook 100MW datacenter, 442k servers. 40% idle means 265k idle servers per day
06:19PM EDT - With our chip, those chips can run AI during downtime
06:19PM EDT - e.g. 256k servers, each with 4x2x100 GbE with no oversubscription

06:21PM EDT - Also saves power
06:21PM EDT - New technology is needed - datacenters could consume 40% of planet energy by 2040
06:22PM EDT - Overall aims
06:22PM EDT - Outperform Xeon E5 v4 using same GCC

06:22PM EDT - 4.0 GHz on 7 nm
06:22PM EDT - Tape out in 2019
06:22PM EDT - Multiple interested and engaged customers
06:23PM EDT - Integer Datapath is in place - currently limited by speed of SRAMs
06:23PM EDT - Q&A time
06:26PM EDT - Q: I feel like deja vu - at Hot Chips, Intel introduced VLIW-concept Itanium that pushed complexity onto the compiler. I see traces of that here. What are you doing to avoid the Itanium traps? How will you avoid IP from Intel? A: Itanium was in-order VLIW, hope people will build compiler to get perf. We came from opposite direction - we use dynamic scheduling. We are not VLIW, every node defines sub-graphs and dependent instructions. We designed the compiler first. We build hardware around the compiler, Intel approach the opposite.
06:27PM EDT - Q: You mention emulation for x86. What kind of penalty in performance? A: About 40% performance loss. Significant because our customer didn't want us to invest in that, as 90% of their software will be natively compiled by next year. It's a temporary deployment. Binary 4.0 GHz emulated still outperforms 2.5 GHz Xeon
06:28PM EDT - Q: How do you dodge the patents in place in this? A: We building a new beast. Our tech is significantly different. This is America.
06:30PM EDT - That's a wrap. Next live blog in 30 mins on IBM.








15 Comments
View All Comments
aryonoco - Tuesday, August 21, 2018 - link
So let me get this straight:This is an in-order CPU that targets high frequencies, and the designers think they can overcome the in-order's limitation by clever compiler? Somehow they'll be able to do what Intel never achieved with Itanium?
And, it's a new ISA, so you have to port everything to it to start with?
And they think QEMU emulation is going to solve their problems?
What are they smoking?! And if these people can get VC money for their crazy pipe dreams, why am I not living in a 19 bedroom mansion?
eastcoast_pete - Wednesday, August 22, 2018 - link
Don't know the answers to your questions, except the last one. Here they are: 1. Because you need to make even more outrageous claims in a colorful slide set to pitch your stuff, and 2. Before said pitch, botox your facial muscles, so you won't smirk or smile when you ask for a gazillion dollars in funding.Let me know how that works out (:
SarahKerrigan - Tuesday, August 21, 2018 - link
Man, that functional unit config is weird. 1 LSU, 1 LU, 1 SU? What the heck kind of workload will ever issue two stores and one load?I also take exception to their criticism of IPF; IPF *did* encode dependent operations, albeit indirectly, using the templating mechanism (an IPF instruction group can be indefinitely wide, as long as it has no internal dependencies; when you run into dependencies you stick in a template that defines a stop.)
To me, this looks like the child of IPF and Power6 (mainly for the runahead parts) - neither of which were incredibly effective microarchitectures at general-purpose workloads through their lifetimes - but I'm willing to be convinced.
name99 - Thursday, August 23, 2018 - link
I think you people are all missing the point.The words that matter here are "We are not VLIW, every node defines sub-graphs and dependent instructions"
This is an Explicit Data Graph Execution design
https://en.wikipedia.org/wiki/Explicit_data_graph_...
MS is researching the exact same sort of thing.
One problem I *think* exists with such designs is that they are not easily modified forward (ie it's difficult to maintain binary compatibility while improving the design each time your process allows you to use more transistors).
BUT I think their assumption is that binary compatibility has had its day -- any modern code (especially in the HPC area they seem to be targeting first) is in source, distribution via floppy disks and CDs is dead, and limiting your design so you can keep doing things the way they were done in the 1990s is just silly.
(This was, of course, the same sort of premise behind Java and .NET.
Those two "failed" [relative to their ambitions] in different ways, but JS succeeded...
Apple seems to be experimenting ever so slowly with the same sort of idea. Right now it's somewhat unambitious --- some post-submission touch-up in the iOS store, and submitting apps in some sort of IR to the Watch store.
Clearly this, consumer, level of abstraction is a harder problem because developers don't want to distribute source, even to the app store; and there are more variations and more things that can go wrong with consumer distribution of an IR. We don't even know how robust Apple's Watch IR will be to when the aWatch goes 64 bit [presumably this year?]
But I think it's becoming ever more clear the win that's available if you are not forced into endless backward compatibility --- think how fast GPUs have been able to evolved because they do not have this constraint. Which means it's just a question of which companies are smart enough to be the first to exploit this...
Perhaps it will be Tachyum in the HPC space, I have no idea.
I expect it will be Apple in the consumer space. MS had their chance, had everything lined up with .NET, but being MS they, of course..., fscked it up because, 15 years after CLR's first release, they STILL can't decide how much to commit to it.
Apple may discover that their current IR is sub-optimal for truly substantial ISA updates; but they are flexible and can and will change. For example they might switch to using SIL as the preferred distribution IR, something that will get ever more feasible as Swift fills out its remaining missing functionality.)
Elstar - Sunday, August 26, 2018 - link
The IR Apple uses is just LLVM IR, which is a fairly transparent IR. You can’t take IR generated by clang or Swift and magically switch endian modes, or pointers size for example, because the ObjC++ or Swift code can generate different ABI data structures depending on the endianness or pointer size. Even if these problems are solved, most vector code is ISA specific and therefore ISA specific LLVM IR is generated. You could try and translate one vector ISA model to another ISA vector model, but the results would never be as fast as people would want or expect.Elstar - Tuesday, August 21, 2018 - link
This feels like the classic "fake it until you make it" silicon valley presentation. I will doubt that most of the promises made in this presentation will ever ship.webdoctors - Wednesday, August 22, 2018 - link
I previously designed something similar, and the difficult part was being able to hit high frequencies due to the timing critical datapath. 1 GHz was feasible, but 4......The overhead of the translation between ISAs also caused a perf hit so the published numbers are very suspicious.
eastcoast_pete - Wednesday, August 22, 2018 - link
I agree that it would be more than just a little bit assuring if they had taped out a small run of anything similar to this, even in 22 nm, and not hitting 4 Ghz; let it hit >2 Ghz in early prototype, that'd be fine. Predictions and simulations are subject to challenge by reality.V900 - Wednesday, August 22, 2018 - link
“Faster than Xeon” and “smaller than ARM” sounds a little too good to be true.What architecture is this? An ARM respin or a brand new one?
eastcoast_pete - Wednesday, August 22, 2018 - link
Interesting design, even after the hype-discount (faster than Xeon, smaller than ARM?). Problem with such designs tends to be the dreaded compiler. From what I can gather, that chip will live or die by its compiler, as that is supposed to allow out-of-order execution on this in-order design.@Ian: Some questions: I know this is "Hot Chips", but have they/will they present at "Hot Compiler" or anything similar? What is known about the compiler?
Tachyum made/makes a big deal about their AI prowess. Did they say what makes their chip so much better for that than existing solutions? And, by better, I don't just mean faster, but performance/Wh.
Lastly, has TSMC confirmed that Tachyum has signed a contract with them, or is it all vaporware/"we plan to.." right now?