AMD Ryzen Threadripper 7980X & 7970X Review: Revived HEDT Brings More Cores of Zen 4
by Gavin Bonshor on November 20, 2023 9:00 AM EST- Posted in
- CPUs
- AMD
- HEDT
- ThreadRipper
- Zen 4
- Threadripper 7000
- TRX50
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
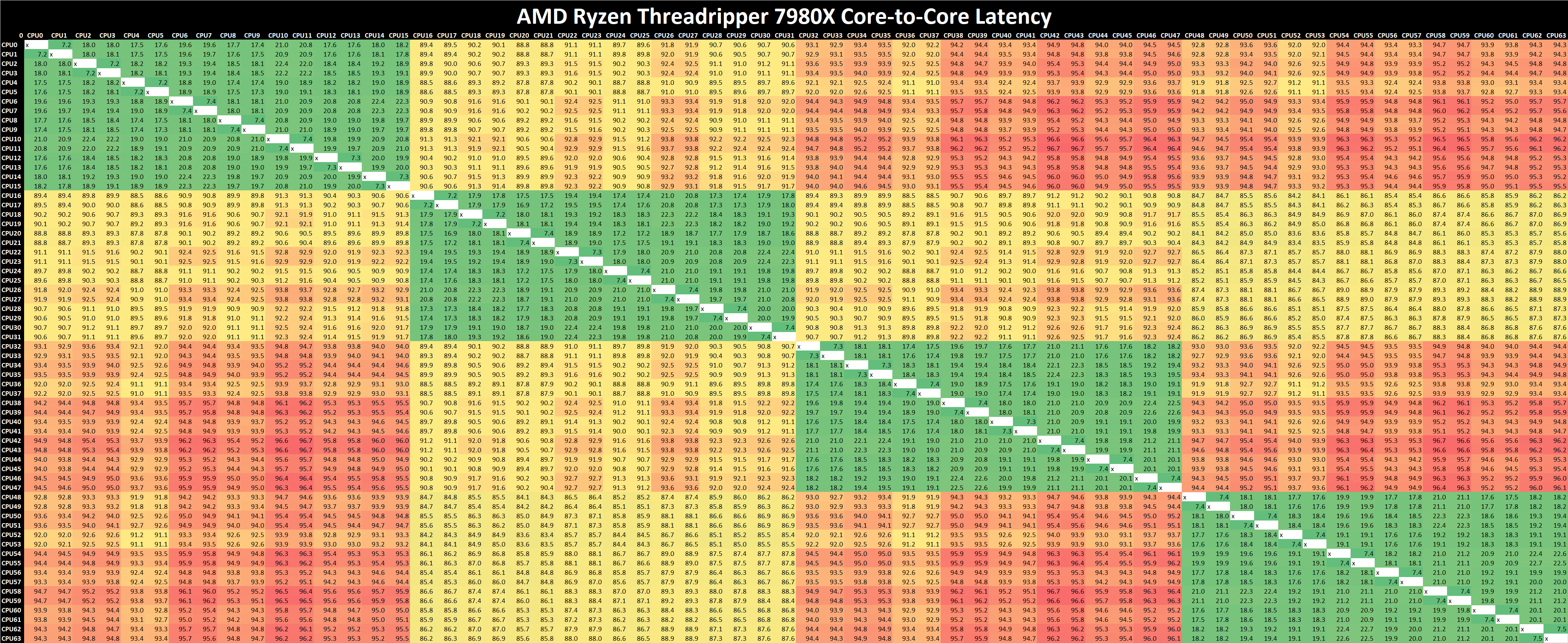
(Click on the image to enlarge)
Analyzing core-to-core latencies on the AMD Ryzen Threadripper 7980X (64C/128T), our test is limited to probing the first 64 threads, although scaling out to 128 threads would be identical. Each CCD on the Threadripper 7980X has 8 x Zen 4 cores, with 32 MB of L3 cache. Looking at the latency range within the CCD, we can see inner latencies between 7 and 20 ns, which increase to 89 and 96 ns as each core communicates within the CCX.

A visual render of the AMD Ryzen Threadripper 7980X with 8 x CCDs and IOD
Given we've reviewed the AMD Ryzen 9 7950X, which has the same Zen 4 cores and the same CCD complex approach to communicating between the cores, we see relatively similar latencies in both Threadripper 7000 and Ryzen 7000. A quad-channel DDR5 memory controller integrated within the large IOD and using PCIe 5.0 lanes as the primary pathway is important in enhancing the Infinity Fabric interconnect to reduce latencies and help counteract any penalties.








66 Comments
View All Comments
JRF68 - Tuesday, December 12, 2023 - link
FYI the Xeon W3300 series (Icelake), introduced 3rd quarter 2021, has 8 channel memory. However the secondhand market for the W3300 is atrocious. On eBay prices for a W3365 are 1200 USD, and that's for a QS sample. The required motherboard from SuperMicro, X12SPA-TF C621A LGA4189 on eBay, are asking 12-1500 USD. So ya, skip it and go new W3400 series, that's what I'm in the process of doing.SanX - Wednesday, November 29, 2023 - link
AVX512 shows 5 times, 8 times, even 10+ times speedup. Can anyone on the planet show me any real app, not the test no one saw the source code, which benefited from AVX512 even by the factor 2-3 ?Frank_M - Tuesday, December 5, 2023 - link
Waves Plug-ins for DAW's.R
Mathematica
Pretty much anything that uses the Intel Math Kernel Library.
SanX - Tuesday, December 12, 2023 - link
And the speedup there is? 10%Frank_M - Tuesday, December 5, 2023 - link
Enjoyed the stats.It would be interesting to read some articles on what would be the best hardware configs to run tensor Flow, One API, and/or GNU Scientific assuming a budget of $5000.
SanX - Wednesday, December 13, 2023 - link
Are Anandtech's Ian Cutress AVX2 and AVX512 codes available for users testing? Are source codes available? On how many cores they work, all or just one?