The Apple A15 SoC Performance Review: Faster & More Efficient
by Andrei Frumusanu on October 4, 2021 9:30 AM EST- Posted in
- Mobile
- Apple
- Smartphones
- Apple A15
CPU ST Performance: Faster & More Efficient
Starting off with this year’s review of the A15, in order to have a deeper look at the CPU single-threaded performance and power efficiency, we’re migrating over to SPEC CPU 2017. While 2006 has served us well over the years and is still important and valid, 2017 is now better understood in terms of its microarchitectural aspects in its components, and becoming more relevant as we moved our desktop side coverage to the new suite some time ago.
One continuing issue with SPEC CPU 2017 is the Fortran subtests; due to a lacking compiler infrastructure both on iOS and Android, we’re skipping these components entirely for mobile devices. What this means also, is that the total aggregate scores presented here are not comparable to the full suite scores on other platforms, denoted by the (C/C++) subscript in the score descriptions.
As always, because we’re running completely custom harnesses and not submitting the scores officially to SPEC, we have to denote the results as “estimates”, although we have high confidence in the accuracy.
In terms of compiler settings, we’re continuing to employ simple -Ofast flags without further changes, to be able to get the best cross-platform comparisons possible. On the iOS side of things, we’re running on the newest XCode 13 build tools, while on Android we’re running the NDKr23 build tools.
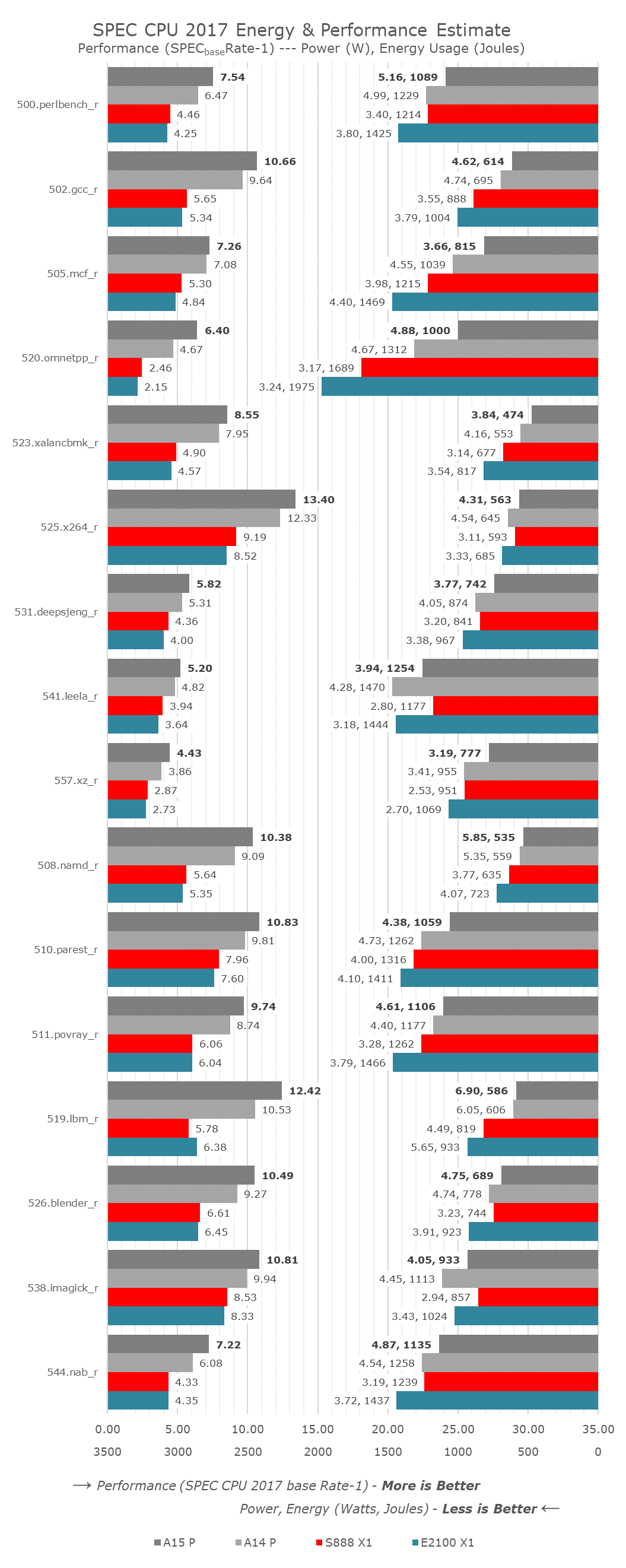
In terms of performance and efficiency details, we’re swapping the graphs around a bit from now on – on the left axis we have the performance scores of the tests – larger bars here mean better performance. On the right-side axis, growing from right to left are the energy consumption figures for the platforms, the smaller the figure, the more energy efficient (less energy consumed) a workload was completed. Alongside the energy figure in Joules, we’re also showcasing the average power figure in Watts.
Starting off with the performance figures of the A15, we’re seeing increases across the board, with absolute performance going up from a low of 2.5% to a peak of +37%.
The lowest performance increases were found in 505.mcf_r, a more memory latency sensitive workload; given the increased L2 latency as well as slightly higher DRAM latency, it doesn’t come too unexpected to see a more minor performance increase. However, when looking at the power and efficiency metrics of the same workload, we see the A15 use up almost 900mW less than the A14, with energy efficiency improving by +22%. 520.omnetpp_r saw the biggest individual increase at +37% performance – power here went up a bit, but energy efficiency is also up 24%.
The smallest performance gains of the A15 are found in the most back-end execution bound workloads, 525.x264_r and 538.imagick_r improve by only 8.7%, resulting in an IPC increase of 0.6% - essentially within the realm of measurement noise. Still, even here in this worst performance case, Apple still managed to improve energy efficiency by +13%, as the new chip is using less absolute power even though clock frequencies have gone up.
The most power demanding workload, 519.lbm_r, is extremely bandwidth hungry and stresses the DRAM the most in the suite, with the A15 chip here eating a whopping 6.9W of power. Still, energy efficiency is generationally slightly improved as performance goes up by 17.9% - based on first teardown reports, the A15 is still only powered by LPDDR4X-class memory, so these improvements must be due to the chip’s new memory subsystem and new SLC.
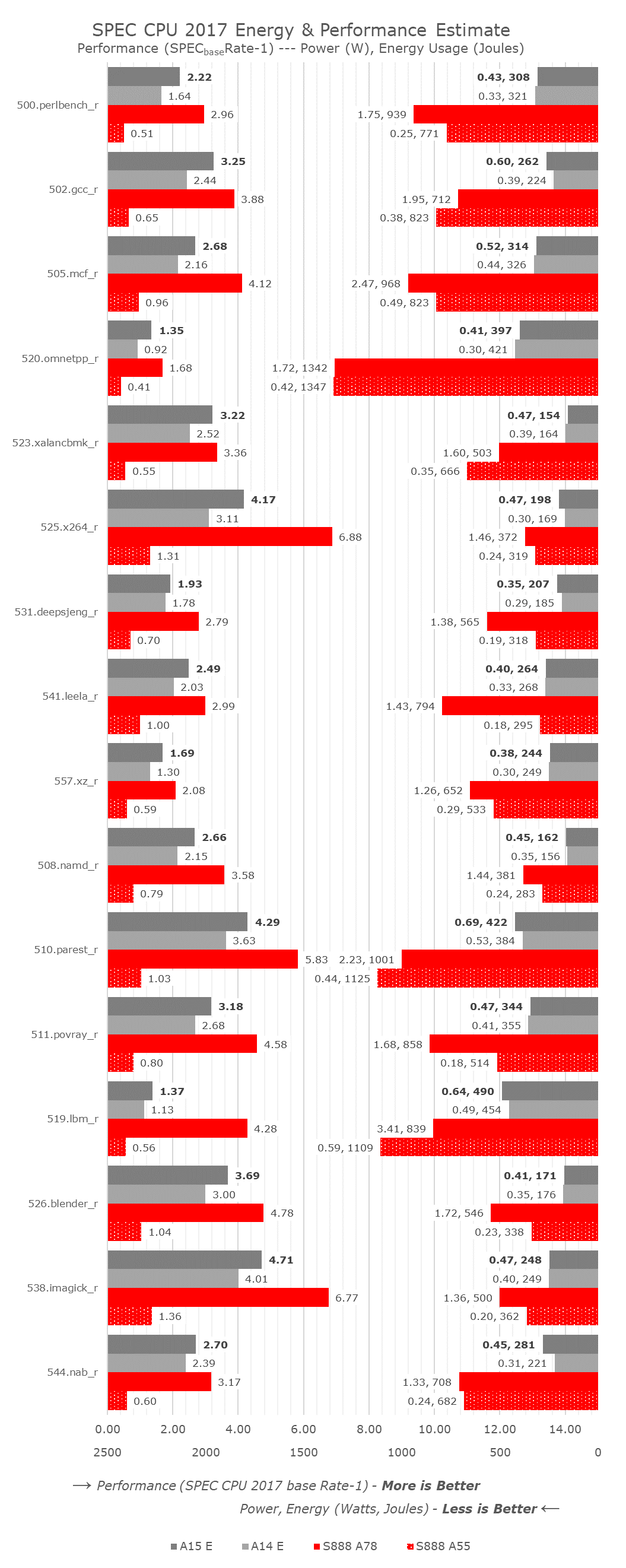
Shifting things over to the efficiency cores, I wanted to make comparisons not only to the A14’s E-cores, but also put the Apple chips in context to the competition, a Snapdragon 888 in this context, comparing against a 2.41GHz Cortex-A78 mid-core, as well as a 1.8GHz Cortex-A55 little core.
The A15’s E-cores are extremely impressive when it comes to performance. The minimum improvement varies from +8.4 in the 531.deepsjeng_r, essentially flat up with clocks, to up to again +46% in 520.omnetpp_r, putting more evidence into some sort of large effective sparse memory access parallelism improvement for the chip. The core has a median performance improvement of +23%, resulting in a median IPC increase of +11.6%. The cores here don’t showcase the same energy efficiency improvement as the new A15’s performance cores, as energy consumption is mostly flat due to performance increases coming at a cost of power increases, which are still very much low.
Compared to the Snapdragon 888, there’s quite a stark juxtaposition. First of all, Apple’s E-cores, although not quite as powerful as a middle core on Android SoCs, is still quite respectable and does somewhat come close to at least view them in a similar performance class. The comparison against the little Cortex-A55 cores is more absurd though, as the A15’s E-core is 3.5x faster on average, yet only consuming 32% more power, so energy efficiency is 60% better. Even for the middle cores, if we possibly were to down-clock them to match the A15’s E-core’s performance, the energy efficiency is multiple factors off what Apple is achieving.
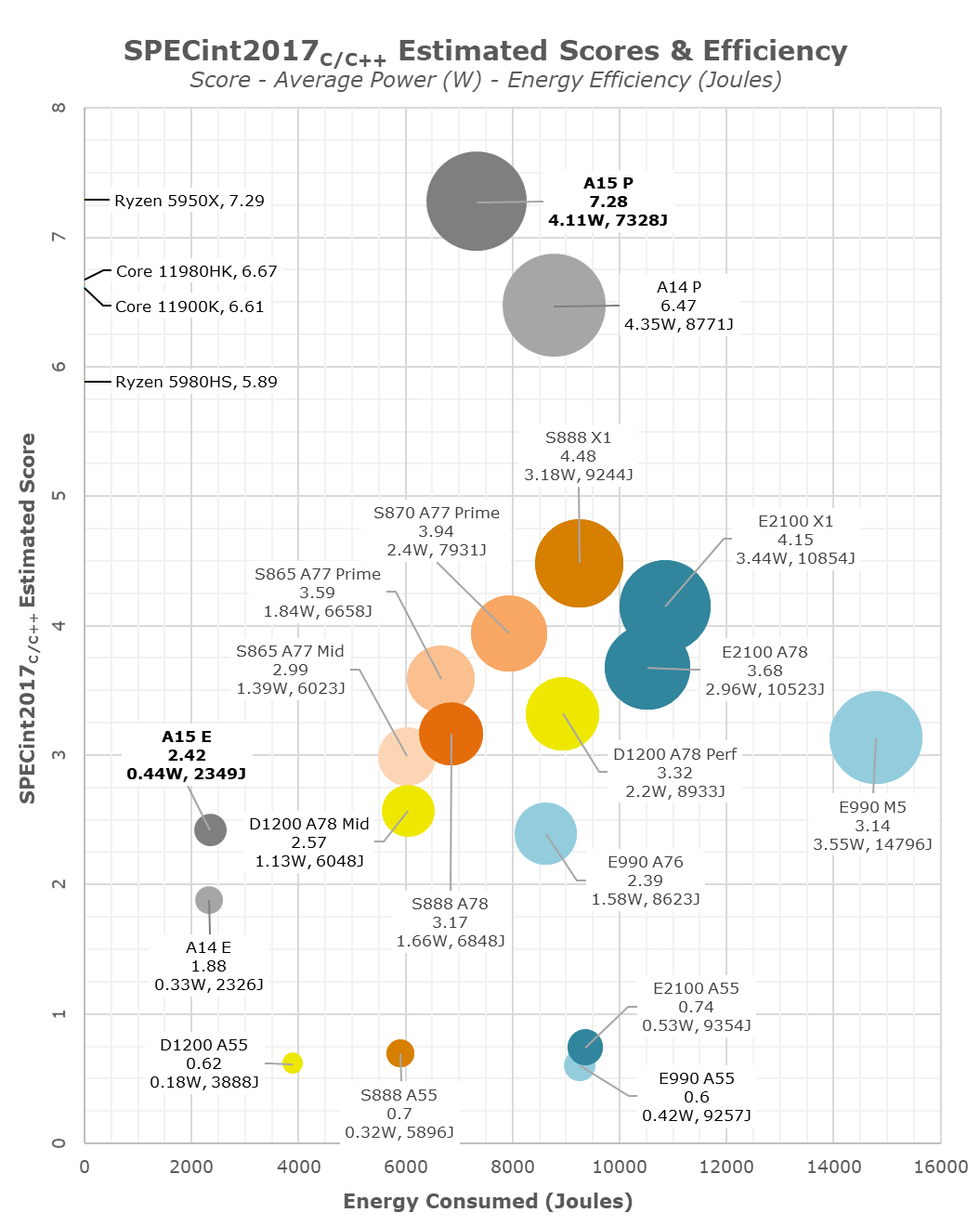
In the overview graph, I’m also changing things a bit, and moving to bubble charts to better spatially represent the performance to energy efficiency positioning, as well as the performance to power positioning. In the energy axis graphs, which I personally find to be more representative of the comparative efficiency and resulting battery life experiences of the SoCs, we see the various SoCs at their peak CPU performance states versus the total energy consumed to complete the workloads. On the power axis graphs, we see the same data, only plotted against average power. Generally, I find distinction of efficiency here to be quite harder between the various data-points, however some readers have requested this view. The bubble size corresponds to the average power of the various CPUs, we’re measuring system active power, meaning total device workload power minus idle power, to compensate components such as the display.
Apple A15 performance cores are extremely impressive here – usually increases in performance always come with some sort of deficit in efficiency, or at least flat efficiency. Apple here instead has managed to reduce power whilst increasing performance, meaning energy efficiency is improved by 17% on the peak performance states versus the A14. If we had been able to measure both SoCs at the same performance level, this efficiency advantage of the A15 would grow even larger. In our initial coverage of Apple’s announcement, we theorised that the company might possibly invested into energy efficiency rather than performance increases this year, and I’m glad to see that seemingly this is exactly what has happened, explaining some of the more conservative (at least for Apple) performance improvements.
On an adjacent note, with a score of 7.28 in the integer suite, Apple’s A15 P-core is on equal footing with AMD’s Zen3-based Ryzen 5950X with a score of 7.29, and ahead of M1 with a score of 6.66.
The A15’s efficiency cores are also massively impressive – at peak performance, efficiency is flat, but they’re also +28% faster. Again, if we would be able to compare both SoCs at the same performance level, the efficiency advantage of the A15’s E-cores would be very obvious. The much better performance of the E-cores also massively helps avoiding the P-cores, further improving energy efficiency of the SoC.
Compared to the competition, the A15 isn’t +50 faster as Apple claims, but rather +62% faster. While Apple’s larger cores are more power hungry, they’re still a lot more energy efficient. Granted, we are seeing a process node disparity in favour of Apple. The performance and efficiency of the A15 E-cores also put to shame the rest of the pack. The extremely competent performance of the 4 efficiency cores alongside the leading performance of the 2 big cores explain the significantly better multi-threaded performance than the 1+3+4 setups of the competition.
Overall, the new A15 CPUs are substantial improvements, even though that’s not immediately noticeable to some. The efficiency gains are likely key to the new vastly longer battery longevity of the iPhone 13 series phones – more on that in a dedicated piece in a few days, and in our full device review.








204 Comments
View All Comments
Transistor Fist - Monday, October 4, 2021 - link
The urge to implement better cooling solutions is only matched by their impressive y-o-y improvements. If they continue like this, their systems will melt like butter in Cupertino summer.michael2k - Monday, October 4, 2021 - link
What are you talking about? Did you read the same article I read? The power/performance of the chips are superb and should allow the Macs, with their larger heat absorbing and dissipating systems, to stay amazingly cool. It’s unlikely Apple will release a 5GHz MBP with this chip.cha0z_ - Tuesday, October 5, 2021 - link
With that PCB design it will be hard to implement any cooling solution that will provide any real difference, especially with the limited space in their phones to even fit the said cooling. I don't really feel they are not doing more because of laziness or to milk people, I really do feel they test a lot and the current solution provides the best balance between power/speed/thermals.name99 - Monday, October 4, 2021 - link
I know you, reader, are not so shallow! But for everyone else out there who just wants a straight-out cage match result, the SPEC2017 numbers for Rocket Lake (same methodology) are here:https://www.anandtech.com/show/16535/intel-core-i7...
It's unfortunate that those results don't show us how much extra AVX-512 (compiler created) gives, but presumably not enough that anyone thinks doing things that way is an outrage. But, quite possibly, most the action in compiler-generated AVX512 would be in the Fortran benchmarks anyway so...
The other caveat in a comparison (apart from Andre's point re Fortran) is that this is the iPhone chip being benchmarked; one suspects the mac chip will, if nothing else, have a larger (shared) L2, perhaps also a larger SLC, perhaps (???) LP-DDR5, and probably another 10% or so higher GHz.
name99 - Monday, October 4, 2021 - link
Someone shared with me some rough AVX512 results compared with AVX2, and there's nothing there. A few small improvements, mostly regressions (presumably frequency limiting).I was trying to be fair in the comment above, that possibly with AVX512 Intel would look a little better -- but it honestly doesn't seem that way; with compiler-generated AVX512 in fact Intel looks essentially the same to very slightly worse.
Spunjji - Friday, October 8, 2021 - link
Apple are making the right choice moving to their own architectures.TristanSDX - Monday, October 4, 2021 - link
PLS, Alder Lake pre-release reviewname99 - Monday, October 4, 2021 - link
"we theorised that the company might possibly invested into energy efficiency rather than performance increases this year"Another way to phrase this which puts the emphasis slightly in a different place, is to assume that the A14 was in fact a rush job, and that in particular physical optimization for N5 was barely performed (hence both sub-optimal transistor usage, and sub-optimal density), and this year more such physical optimization could be performed.
The Tech Insights high-res A15 die shots are now out, so people who like to do this sort of thing can get to pixel measuring and calculating relative sizes. My quick and dirty estimates (based on early numbers, not the current die shot) are that density increased about 7%. That hardly gets us to the maximum possible density TSMC suggests for N5, but does suggest that some fraction of the surprisingly low A14 density was simply lack of time to optimize.
mukiex - Monday, October 4, 2021 - link
This is awesome! I was worried we wouldn't get an iPhone SoC review, but a review of JUST the SoC? I'm 100% on board with this being Anandtech's approach moving forward.eastcoast_pete - Monday, October 4, 2021 - link
Thanks Andrei! As a long-time Android user, one of the most frustrating aspects of current and future stock-ARM SoCs (currently, pretty much all Android phones) was the decision by ARM to keep the efficiency cores as in-order designs. Your tests of the current Apple SoC alongside the 888 and Exynos show just how much energy efficiency was left on the table with the A55. I know that ARM claims that their new efficiency core design is improved over the A55, but, as it remains in-order, I don't see how they can get even close to the efficiency cores in Apple's SoC.The simple truth is that being able to run mostly on the efficiency cores has great upsides for battery life. In this regard, I applaud Apple: have the high performance on the large cores when needed, keep the rest on the efficiency cores if possible without ruining the user experience.