Improving The Exynos 9810 Galaxy S9: Part 1
by Andrei Frumusanu on April 4, 2018 10:00 AM EST- Posted in
- Mobile
- Samsung
- Smartphones
- SoCs
- M3
- Exynos 9810
- Galaxy S9
Last week we published our Galaxy S9 and S9+ review, and the biggest story (besides the device) was the difference between the processors used inside the two variants: the Snapdragon 845 SoC and Exynos 9810 SoC. Based on earlier announcements, we had large expectations from the Exynos 9810 as it promised to be the first “very large core” Android SoC. However, our initial testing put a lot of questions on the table. Unfortunately the synthetic performance of the Exynos 9810 did not translate well at all into real life performance. As part of the testing, I had discovered that the device’s scheduler and DVFS (dynamic voltage-frequency scaling) configurations were atrociously tuned.
For the full review I had opted not to go modify the device, as that initial review was aimed as a consumer oriented article, and it would serve little purpose to readers (that and time constraints). Still I promised I would follow up in the coming weeks and this is the first part of what’s hopefully a series where I try to extract as much as possible out of the Exynos 9810 and alleviate its driver situation.

After rooting the device and getting a custom kernel up and running, one of the first things I did was to play around with the hotplugging mechanism that I explained in the review article was what is in my opinion the most damaging to performance.
One of the benefits the custom kernel is pushing the frequencies, and so after a bit of fun playing around a bit I achieved GeekBench multi-core records at 4x 2496MHz on the M3 cores. Trying to run the M3 cores at 2704 MHz consistently crashed the phone, so I decided it’s better to start at the bottom and work our way up the performance scale.
Configuration Overview And SPEC
| Samsung Galaxy S9 (E9810) Kernel Comparison and Changelog |
||
| Version | Changes and Notes | |
| Official Firmware | As Shipped | - Stock setup and behavior - Single Core M3 at 2704 MHz - Dual Core M3 at 2314 MHz - Quad Core M3 at 1794 MHz |
| 'CPU Limited Mode' |
- Optional Samsung-defined CPU Mode in Settings - CPU limited to 1469 MHz - Memory controller at half-speed - Conservative Scheduler |
|
| Custom Config 1 | - Start with 'As Shipped' Firmware - Remove hotplugging mechanism - Limit M3 frequency peak to 1794MHz at any loading |
|
For the first round of testing, I judged the hotplugging mechanism as a whole is better off to be completely disabled, as it just doesn’t manage to serve its purpose. The frequency for the M3 cores was set fixed at 1794 MHz, the same frequency as the shipping kernel gives when all four M3 cores are in play. Technically, based on frequency alone, this should theoretically result in the same multi-threaded performance, and worse single core performance.
And here’s where the interesting things start. At 1794MHz the Exynos M3 performed extremely well and ended up above my expectations in synthetic benchmarks. Starting off with SPEC:
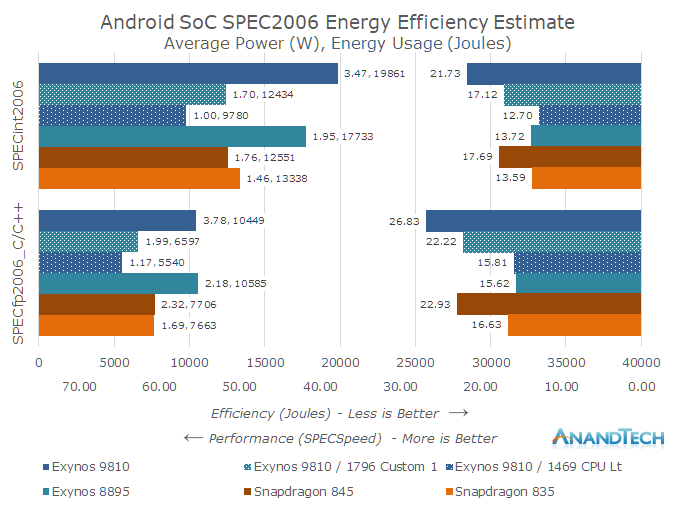
In the Galaxy S9 review article I had made the hypothesis that for the equivalent peak performance of the Snapdragon 845, the Exynos 9810 would lose in efficiency. In the review, I extrapolated the energy increase with as the frequency rises using the CPU Limiter figures at 1469MHz. Based on those first results, I suggested that the Exynos 9810 would need to be at 2.1-2.3GHz to match the Snapdragon 845 in SPEC.
To my surprise, the results at 1794MHz closely matched the Snapdragon 845’s peak figures within a couple of percentage points. Not only did the 9810 match the 845 in performance, but the efficiency metrics were also beating expectations. In SPECint, the Exynos now matches the energy usage of the Snapdragon. In SPECfp, the Exynos even now retains a 15% efficiency lead.
This time I included back a second graph for SPEC – I’m still conflicted to show the data here this way, as the metric is 'work per time per energy' or 'performance per energy' and I’m still struggling to come up with an immediately intuitive explanation as what is being showcased, I ended up calling it 'Performance Efficiency' as the most fitting term. Readers here need to carefully disambiguate the term “efficiency” between total energy usage (representative of battery usage) and this “performance efficiency” metric which is more ethereal in its meaning.
How this difference between the three setups is happening is something that I at the moment attribute to three factors: the removal of the hotplugging mechanism removes any ST performance noise from other threads, the M3 cores are being better utilized at the lower frequencies, and we’re just seeing some gains in thermal limited workloads such as libquantum.
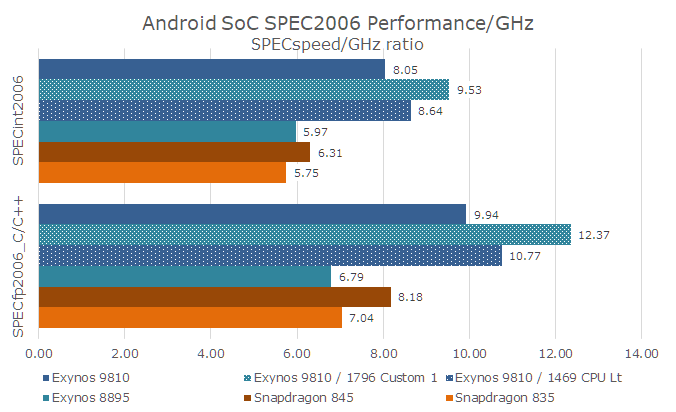
The second reason is I think the most important here as the M3 cores are better served by the conservative memory controller DVFS. This is extremely noticeable in the SPECfp results, as the 1794 MHz scores end up with a 'SPECspeed per GHz' ratio (a measure of performance efficiency) of 12.37 - this is compared to a ratio of 9.94 for the stock kernel runs. This translates to a 24% increase in measured IPC efficiency. The SPECint results also improve that performance/GHz ratio, rising from 8.05 to 9.53, correlating to an 18% increase.
In the earlier SPECspeed/Joules (Performance Efficiency) graph, we see how the 1794MHz results fare better than the stock and CPU limiter results. This difference isn’t displayed in the total energy or perf/W metrics so there is credit to showcasing the results this way.
Overall, with these current best-case results, the M3 cores offer a 51% IPC advantage over the Kryo 385 Gold cores in the Snapdragon. This is a lot nearer to what we expected from the core based on the initial announcements and microarchitecture.
System Performance
I argued in the Galaxy S9 review that the real-world performance of the Exynos variant was hampered by software and that workloads never really got to make use of the raw performance. Let’s quickly revisit the benchmarks and see what the results of the first changes in the kernel running at 1794 MHz.

PCMark’s Web Browsing 2.0 test sees a significant 22% boost in performance over the stock configuration. Again I argued that the hotplugging mechanism was in many cases extremely detrimental to real-world performance as its coarse nature simply did not manage to efficiently control the finer-grained behaviour of threads in many workloads. The result here speaks for itself, as even though the new custom kernel significantly limits raw single threaded CPU performance compared to stock, the web test just does so much better.

The video editing test saw a small performance degradation here, I will try to investigate this more later on.
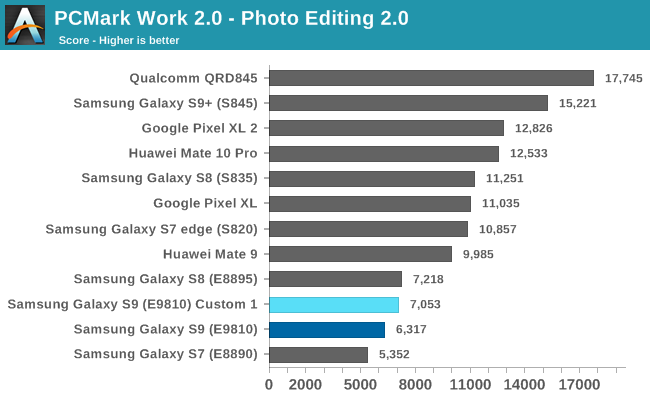
Photo editing test saw an increase in performance.
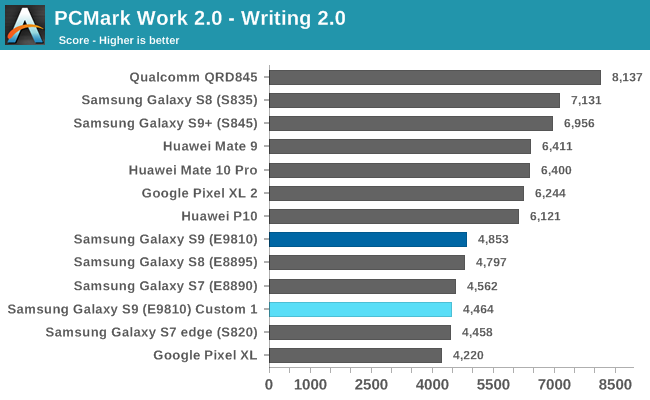
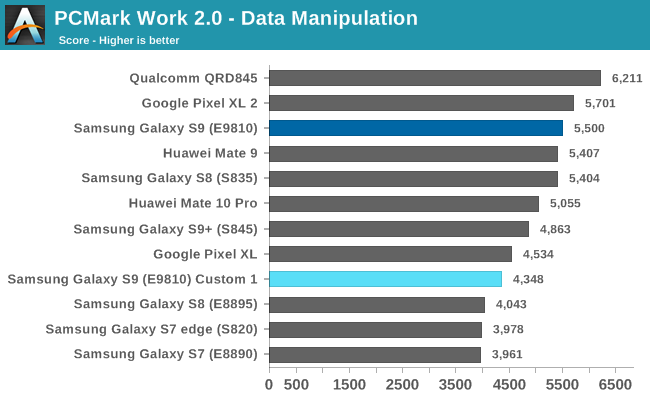
The Writing 2.0 and Data Manipulation tests saw degradations, with the latter one seeing the biggest downside of the frequency limiting. I’m extremely confident that I’ll be able to recoup these degradations with further tuning as I haven’t yet touched the scheduler and DVFS behaviours of the phone.
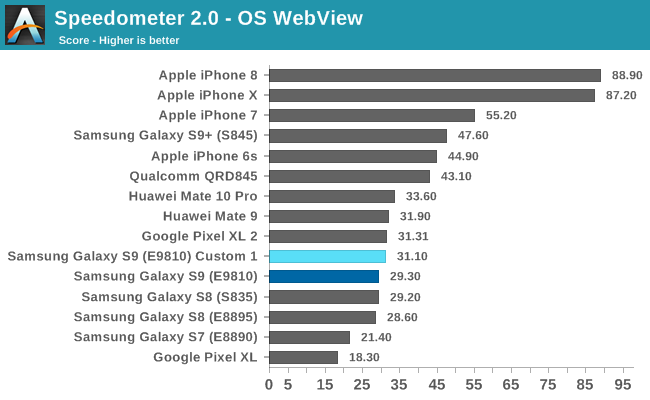
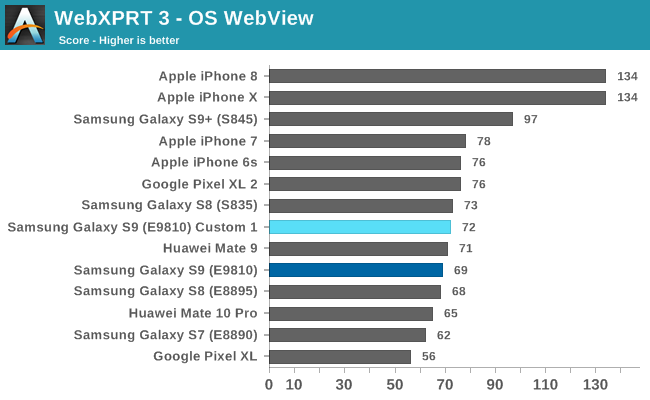
Finally, in the web tests the performance of this first custom configuration again provides a better score than the stock behaviour, which is ironic, as web workloads are meant to be the one scenario where the ST performance is meant to manifest itself the most. I’ll refer back to my “The Mobile CPU Core-Count Debate: Analyzing The Real World” from a few years back where we saw that this actually might not be the case and today’s browsers are actually more multi-threaded as one might think.
The issue again with the Exynos 9810’s current mechanism in the S9 is that it’s trying too hard, and biasing too much towards ST performance at the cost of MT performance. As a result, as our results show, the whole thing falls down like a house of cards.
Battery Life Regained
Finally, the most important metric is to see how the S9 fares in terms of battery life under these settings.
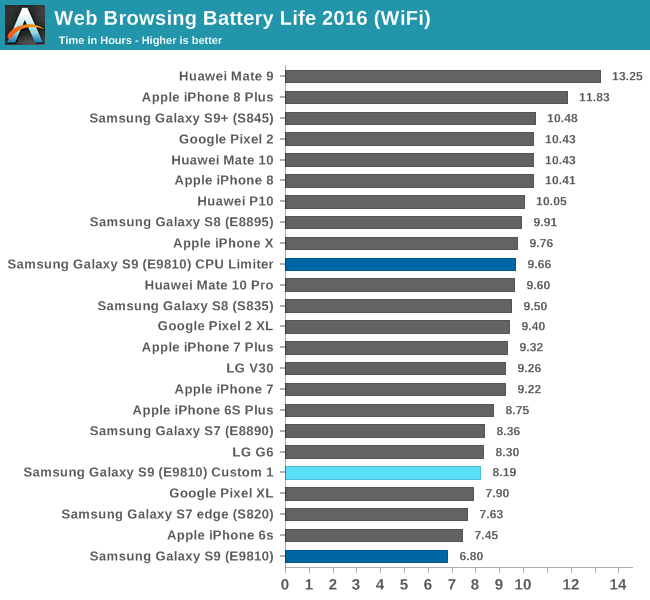
The Exynos S9 was able to improve by 20% and regain 1h23m in our web browsing test which is a good improvement given the low effort. Given the fact that the changes made with the this first custom kernel were, in the vast majority of scenarios, favourable for web browsing performance, this feels to me like another nail to the coffin towards Samsung’s mechanisms. The higher frequencies on the M3 CPU as provided in the shipping kernel simply aren’t beneficial in real-world scenarios, as the software just doesn’t (and likely just can’t) make proper use of them.
Today’s results are just meant as a quick preview of the Exynos S9’s behaviour when removing what I believed the most offending parts of Samsung’s mechanisms. The results are very promising as we are essentially getting real-world performance boosts while at the same time seeing efficiency improvements and battery life improvements.
There is still a lot to be done - I haven’t really touched the scheduler or DVFS scaling logic, but I’m confident that it’s possible to improve things further. It’s unlikely that we’ll end up matching the Snapdragon 845 variant in battery life, as there are efficiency curve considerations at lower performance points that simply cannot be changed through software. But closing the gap as much as possible seems to be an attainable short-term goal.
We have not yet had official commentary from Samsung on the situation yet, but the likelihood that we’ll see significant changes introduced through firmware updates seem slim to me. For now, unless you’re one of the very few enthusiast people into modifying your mobile devices, then the above results are relatively meaningless for a consumer and should not be used for purchasing guidance, for which I refer back to my conclusions in the S9 and S9+ review.
Original carousel image credit to Terry King








65 Comments
View All Comments
x4nder - Wednesday, April 4, 2018 - link
hi, that was a good read. What I don't understand though is why you said it's unlikely that significant changes introduced through firmware updates. Any reasons why Samsung won't try to fix it if it's a software problem?Andrei Frumusanu - Thursday, April 5, 2018 - link
In past Galaxy devices I've never seen Samsung change anything in regards to the SoC behaviour and they stuck with the BSP settings for the lifetime of the device.serendip - Saturday, April 7, 2018 - link
I'm surprised they won't change BSP settings because they're also the SoC vendor. Or maybe the chipset division people don't talk to the mobile devices people.darkich - Thursday, April 5, 2018 - link
Actually it just hit me what this whole mess up could be about..it's just Samsung deliberately crippling their chip to keep it on par with the SD845..and going too far with it/doing a bad job.Quantumz0d - Thursday, April 5, 2018 - link
Did you read the review, I think its not just limiting factor of the 9810 to match the 845. The way its designed is bad. Its a power hungry chip, they only made waves with the new GB scores, if you look past that bench and see the size of the die and the power hungry nature like A11 it falls of a cliff. The wider bandwidth is surely welcoming but at the cost of the thermal efficiency when the phone is made of glass and has limited area to offload the heat it will be a sour grape.The GPU also has been given low importance and not being upgraded due to the CPUs power needs. Considering the small area of improvising and the tuning. Samsung deliberately left the behind the screens part.
Hotplugging is worst when it comes to the >SD810 SoC flagship chips. 820 will choke if you do that. Instead they need to tune it with efficiency.
Still I like that Flar2 is developing for this device. Given the fact that the SD is locked and OP6 is notched. Exynos S9+ is the best package. Still gotta see how HTC does (usually conservative) and Pixel 3 is long time wait..
ZolaIII - Thursday, April 5, 2018 - link
Don't worry S845 is also horrible design, well S810 whose worse & S82x whosent good one either.You are silly. Their is not enough core's that you can turn some down on S82x as a matter of fact best thing you could do is transform it into not heterogeneous one, limit the so cold high performance ones to the frequency of so called efficient ones then you could actually hotplug cores 03 & 04 but I don't think any of that would work as I think it's physical two detached cluster design. S82x is the probably worst design ever from engineering standpoint.
Size of the core/instructions true output at given frequency = efficiency. If M3 is 33% bigger than A75 while having 30% higher instruction true output it will be equally fast as A75 running at 2.6GHz being on 2GHz while becoming more power efficient as leaking is very bad (better say insane) when you cross 2GHz barrier meaning at 2.6GHz power consumption is double. We can only build wider core's now if we want more performance as silicone limit is reached long time ago.
Quantumz0d - Friday, April 6, 2018 - link
What you wrote is it anywhere near to what I said and you speak like as you are a HW expert but fail to make simple communication.Read sultan thread on hotplugging. That's all I can say and 82x is worst ? Better go and join Qcomm and maybe you can design the world's most powerful & efficient soc.
ZolaIII - Friday, April 6, 2018 - link
Now you probably won't ever understand it but hire it goes anyway.The scheduling priority goes this way; HMP sched has priority over CPU sched & it places tasks on ready & available cores in the manner of first suitable core idling or if their is no core idling on the least utilised one if all core's are high utilised & they are over implied task packing rule (tunable) it will wait until their is an available core that meats the criteria. He doesn't play poker nor looks in the crystal ball has no knowledge nor cares about cores that are shot down. CPU sched tries to manage CPU frequencies the way it's written or to the applied additional rules regarding utilisation/frequency, there ware hybrid hotplug cpu sched solutions but they never played very well as CPU sched simply doesn't control CPU task placing. Hotplugging is slow not because a software but because every core must do pos when coming up & for both the core & memory sub system belonging to it & only then HPM sched can issue a placement or migration to it this takes up to around 200ms at least (that's in most cases 10 or more ticks from schedulers) compared to the idling core in which case this is down to: 20ms direct placing, 50~70 side migration on the same cluster, 75~160 up and down migration between clusters.
But hire is the real catch if you have one big or litle core is idling & migrated/started task is SMP 2 (as most of them are) that core will wait until the other one is ready spending power & not doing anything. So that is the answer to your bla bla S82x worst ever... Hotplugging as hotplugging simply doesn't have any sense on 2+2 only SoC which by the way it's the worst one ever as analogy to used core's & typology is trying to kill a fly with a hammer & as their is more fly than things get worse. So it's very inefficient. At the end is the usage of the hotplugging useful and recommended at all? Yes it is on the octa (or hexa core more limited) but it needs to be good configured so that it doesn't cause problems & stalls to the HPM task scheduling because big cores are very power hungry and for some workloads like gaming it's even possible to save a little juice on small core's and what ever additional headroom you provide to GPU it's more than welcome. Bottom line is you need at least two of each core's in active state all the time, if you are a lite user four small ones & one big one on will give better results (reading, scrolling) regarding power consumption but as their is no such a thing as light use as Browser, social network apps, chats are all notorious by their high performance requests burst tasks final results are neglect able with marginal difference in power consumption between the two only 2+2 will be faster to respond (snappier). With good configurable hotplug on up to A55/A75 with cores that use shared L2 cache per pair of them (not applicable to A53's before r02) it's possible to score an additional 5% performance boost with no efficiency penalty using 2+2 setup & on octa big.little SoC's by simply choosing every first core of the pair to be the one always on (all L2 used & with exclusive access all the time + faster pos of other core as their is one less init lv to be done).
Quantumz0d - Friday, April 6, 2018 - link
I understand the first post was exhausted yesterday, so it flew above. About the second post, I appreciate your time for that. I can understand what you mean regarding the Octa with the big.Little vs Quad 82x it seems like similar to the Ryzen CCX, HW limitation.ZolaIII - Friday, April 6, 2018 - link
Well not exactly unfortunately S82x is heterogeneous two cluster system same as octa big.little one's like S835 would have been better that it whose an ordinary single cluster old fashion SoC like S800 as then you could use hotplug & so on. I tried to explain that in the first post. It's beyond me and common sense why QC used big cores for the power efficient cluster on S82x. Also part about core size/ instruction output also in the first post ties only for OoO vs OoO core's as even best OoO design ever the A73 uses 3x power while providing 1.8x integer performance per MHz compared to in order A53's. On FP tasks it's entirely better to use in order A53's (only 28% performance difference while 3x power difference remains the same) but we can't control task placement like that (at least not yet).