Intel Confirms 8th Gen Core on 14nm, Data Center First to New Nodes
by Ian Cutress on February 9, 2017 6:52 PM EST- Posted in
- CPUs
- Intel
- Core 8th Gen
- Cannon Lake

A quick news piece on information coming out of Intel’s annual Investor Day in California. As confirmed to Ashraf Eassa by Intel at the event, Intel’s 8th Generation Core microarchitecture will remain on the 14nm node. This is an interesting development with the recent launch of Intel’s 7th Generation Core products being touted as the ‘optimization’ behind the new ‘Process-Architecture-Optimization’ three-stage cadence that had replaced the old ‘tick-tock’ cadence. With Intel stringing out 14nm (or at least, an improved variant of 14nm as we’ve seen on 7th Gen) for another generation, it makes us wonder where exactly Intel can promise future performance or efficiency gains on the design unless they start implementing microarchitecture changes.
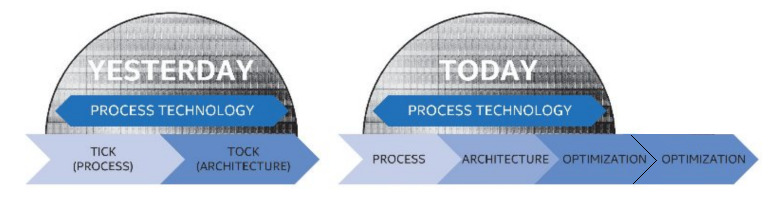
Despite this, if you were to believe supposed ‘leaked’ roadmaps (which we haven’t confirmed from a second source as of yet), the 8th Generation product ‘Cannon Lake’ is more geared towards the Y and U part of Intel’s roadmap. This would ring true with a mobile first strategy that Intel has mirrored with recent generations such that the smaller, low power chips are off the production line for a new product first, however we'd also expect 10nm to also be in the smaller chips first too (as demonstrated at CES). Where Cannon Lake will end up in the desktop or enterprise segment however remains to be seen. To put something a bit more solid into this, Ashraf also mentioned words from Dr. Venkata ‘Murthy’ Renduchintala, VP and GM of Client and IoT:
‘Murthy referred to it at the event, process tech use will be ‘fluid’ based on segment’.
If one read too much into this, we may start seeing a blend of process nodes for different segments at the same time for different areas of the market. We already do have that to some extent with the mainstream CPUs and the HEDT/Xeon families, but this phrasing seems that we might get another split between consumer products or consumer and enterprise. We may get to a point where Intel's 'Gen' naming scheme for its CPUs covers two or more process node variants.
Speaking of the Enterprise segment, another bit of information has also surfaced, coming from a slide during a talk by Diane Bryant (EVP/GM of Data Center) and posted online by Ashraf. The slide contains the words ‘Data center first for next process node’

We can either talk about process node in terms of the ‘number’, either 14nm/10nm/7nm, or by variants within that process (high power, high efficiency). One might suspect that this means Intel is moving hard and fast with 10nm for Xeons and big computing projects, despite showing off 10nm silicon at CES earlier this year. That being said, it’s important to remember that the data center market is large, and includes high-density systems with many cores, such as Atom cores, and Intel did recently open up its 10nm foundry business to ARM Artisan IP projects. So while the slide does say ‘Data center first’, it might be referring to DC projects based on ARM IP in that segment rather than big 4-24+ core Xeons. At this stage of the game it is hard to tell.
On top of all this, Intel still has extreme confidence in its foundry business. An image posted by Dick James of Siliconics from the livestream shows Intel expects to have a three-year process node advantage when its competitors (Samsung, TSMC) start launching 10nm:

I’ve been brief with this news for a reason - at this point there are a lot of balls in the air with many different ways to take this information, and the Investor Day is winding down on talks and finishing with smaller 1-on-1 meetings. We may get further clarification on this news as the day goes on.
Update 1: On speaking with Diane Bryant, the 'data center gets new nodes first' is going to be achieved by using multiple small dies on a single package. But rather than use a multi-chip package as in previous multi-core products, Intel will be using EMIB as demonstrated at ISSCC: an MCP/2.5D interposer-like design with an Embedded Multi-Die Interconnect Bridge (EMIB).
An Intel Slide from ISSCC, via PC Watch
Initially EMIB was thought of as a technology relating to Intel's acquisition of Altera and potential future embedded FPGA designs, and given the slide above and comments made at the Investor Day, it seems there are other plans for this technology too. The benefit of using multiple smaller dies over a large monolithic 600mm2 die is typically related to cost and yield, however the EMIB technology also has to be up to par and there may be a latency or compatibility trade-off.
Source: Intel, @TMFChipFool








124 Comments
View All Comments
Technewsicologist - Friday, February 10, 2017 - link
Intel is claiming that their 14nm process has held a logic cell area advantage over competitors' 14nm and 16nm processes. This is true. However, when Samsung and TSMC release 10nm, those companies will have a density lead (until Intel launches its 10nm).Meteor2 - Sunday, February 12, 2017 - link
Remember those 10 nm nodes are only half nodes though. Much of those chips will be 14 nm still, just as 14/16 nm use 20 nm. Indeed, it's likely that 10 nm will use 20 nm sections.Only Intel nodes and GF's future 7 nm node are full nodes.
Wilco1 - Sunday, February 12, 2017 - link
No that's not true. TSMC 10nm doubles density vs 16nm, so definitely a full node. 7nm is a bit less than a full node.Also it's not just density that matters - 14/16nm FinFET was a full node due to significant performance and power improvements, not in terms of density. TSMC 12nm is a halfnode as it is a tweaked 16nm process.
Technewsicologist - Sunday, February 12, 2017 - link
I am of the opinion that 14nm/16nm, 10nm, and 7nm are full nodes. Each offers about a 0.7x density scaling over its predecessor.Meteor2 - Thursday, February 16, 2017 - link
That's the front end of line, i.e. ignoring the back end of line. Here's a good explanation:http://wccftech.com/intel-losing-process-lead-anal...
gurok - Sunday, February 12, 2017 - link
Actually, that's future perfect tense.lopri - Friday, February 10, 2017 - link
Process > Architecture > Optimization > Optimization > .. > (oops another) Optimization?jjj - Friday, February 10, 2017 - link
It's shameless to publish that process slide and not point out the big fat lie.Intel starts production on 10nm this year and ships in volumes next year, if there are no complications.
TSMC starts 7nm production in Q4 and ships in volume in Q1-Q2, more Q2 really.
Intel's lead is a few months at best, you know it, we know it, but you decide to just publish the lie.
lilmoe - Friday, February 10, 2017 - link
Shameless indeed. Not to mention the "density" claim from the entire blogsphere. It turns out that Ryzen chips on Samsung/GF 14nm will have smaller surface area than equivalent Intel parts, all while having larger L2. In the matter of fact, equivalent size of L2 and L3 cache on Samsung/GF 14nm is significantly smaller.I'm putting money that size isn't the only false claim. Leakage? hmmm.
This lead claim by Intel, and those reporting on it is getting ridiculous. Intel process nodes are no where near as superior as everyone claims to be.
BurntMyBacon - Friday, February 10, 2017 - link
Not sure how the density ends up higher when every reported feature size measurement ends up larger.http://www.eetimes.com/document.asp?doc_id=1331317...
Of particular note is the 6t SRAM which is 0.0806 mm[s]2[/s] vs competitor A's 0.0588 mm[s]2[/s]. The fact that the L2 and L3 cache have better density in Zen despite the universally larger features sizes in the same table is clearly not a process advantage, but likely a difference in layout. It is entirely possible that Intel chose to use a less dense layout to increase speed and/or decrease latency.
Intel is most certainly painting their process in the best light possible, but lets not pretend that TSMC, Samsung, GF, Et al aren't doing the same thing. It is quite the rosy theory that Intel's 14nm process is equal to Samsung's 10nm. However, it would also be a mistake to assume that Samsung's 14nm process is equal to Intel's 14nm process.
That all said, process nodes have ceased bringing the kind of frequency gains that they once did. Efficiency gains are also being offset by increased leakage on smaller process nodes. Even cost savings aren't quite as great due to higher defect rates. Getting more transistors on a die does allow for some nice performance and/or efficiency gains, but when defect rates limit your die size, then similar transistor gains can be achieved on the previous process node at the cost of more die area. The point is, while being several process nodes behind, as AMD remains until Zen launches, is still a significant disadvantage, being a single or half a process node behind doesn't have the same meaning that it once had.