The Bulldozer Review: AMD FX-8150 Tested
by Anand Lal Shimpi on October 12, 2011 1:27 AM ESTThe Architecture
We'll start, logically, at the front end of a Bulldozer module. The fetch and decode logic in each module is shared by both integer cores. The role this logic plays is to fetch the next instruction in the thread being executed, decode the x86 instruction into AMD's own internal format, and pass the decoded instruction onto the scheduling hardware for execution.
AMD widened the K8 front end with Bulldozer. Each module is now able to fetch and decode up to four x86 instructions from a single thread in parallel. Each of the four decoders are equally capable. Remembering that each Bulldozer module appears as two cores, the front end can only pick 4 instructions to fetch and decode from a single thread at a time. A single Bulldozer module can switch between threads as often as every clock.
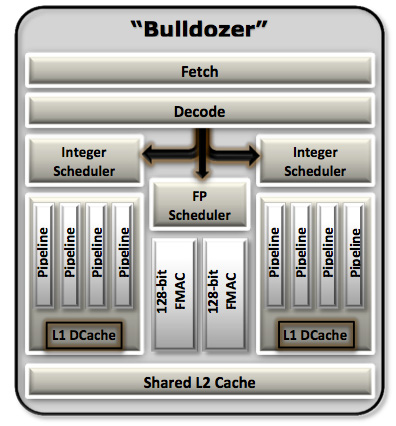
Decode hardware isn't very expensive on its own, but duplicating it four times across multiple cores quickly adds up. Although decode width has increased for a single core, multi-core Bulldozer configurations can actually be at a disadvantage compared to previous AMD architectures. Let's look at the table below to understand why:
| Front End Comparison | |||||
| AMD Phenom II | AMD FX | Intel Core i7 | |||
| Instruction Decode Width | 3-wide | 4-wide | 4-wide | ||
| Single Core Peak Decode Rate | 3 instructions | 4 instructions | 4 instructions | ||
| Dual Core Peak Decode Rate | 6 instructions | 4 instructions | 8 instructions | ||
| Quad Core Peak Decode Rate | 12 instructions | 8 instructions | 16 instructions | ||
| Six/Eight Core Peak Decode Rate | 18 instructions (6C) | 16 instructions | 24 instructions (6C) | ||
For a single instruction thread, Bulldozer offers more front end bandwidth than its predecessor. The front end is wider and just as capable so this makes sense. But note what happens when we scale up core count.
Since fetch and decode hardware is shared per module, and AMD counts each module as two cores, given an equivalent number of cores the old Phenom II actually offers a higher peak instruction fetch/decode rate than the FX. The theory is obviously that the situations where you're fetch/decode bound are infrequent enough to justify the sharing of hardware. AMD is correct for the most part. Many instructions can take multiple cycles to decode, and by switching between threads each cycle the pipelined front end hardware can be more efficiently utilized. It's only in unusually bursty situations where the front end can become a limit.
Compared to Intel's Core architecture however, AMD is at a disadvantage here. In the high-end offerings where Intel enables Hyper Threading, AMD has zero advantage as Intel can weave in instructions from two threads every clock. It's compared to the non-HT enabled Core CPUs that the advantage isn't so clear. Intel maintains a higher instantaneous decode bandwidth per clock, however overall decoder utilization could go down as a result of only being able to fill each fetch queue from a single thread.
After the decoders AMD enables certain operations to be fused together and treated as a single operation down the rest of the pipeline. This is similar to what Intel calls micro-ops fusion, a technology first introduced in its Banias CPU in 2003. Compare + branch, test + branch and some other operations can be fused together after decode in Bulldozer—effectively widening the execution back end of the CPU. This wasn't previously possible in Phenom II and obviously helps increase IPC.
A Decoupled Branch Predictor
AMD didn't disclose too much about the configuration of the branch predictor hardware in Bulldozer, but it is quick to point out one significant improvement: the branch predictor is now significantly decoupled from the processor's front end.
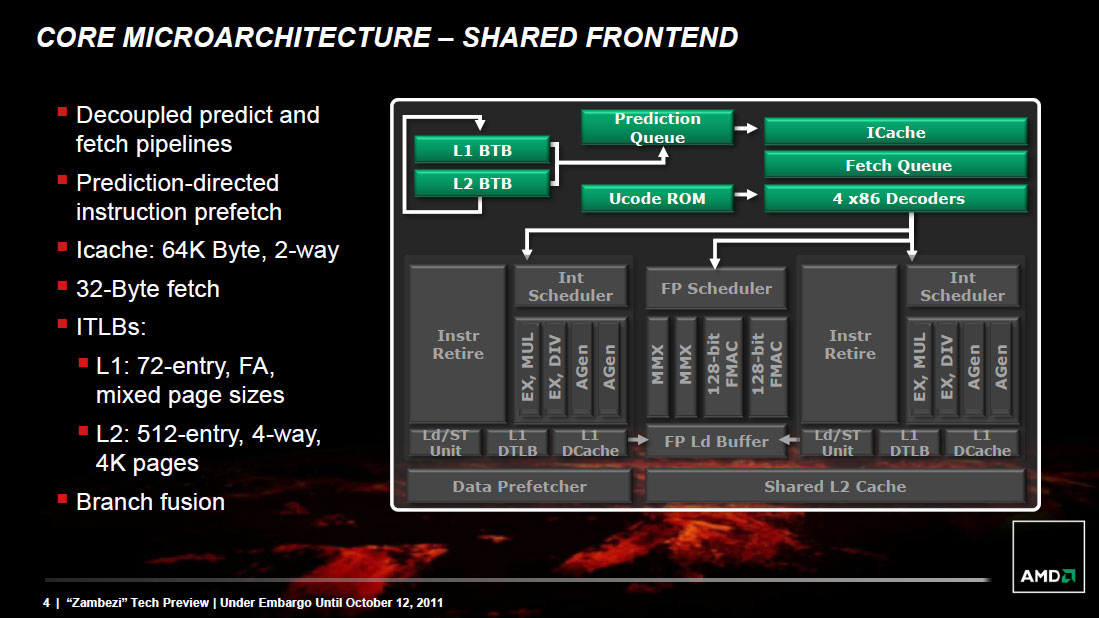
The role of the branch predictor is to intercept branch instructions and predict their target address, rather than allowing for tons of cycles to go by until the branch target is known for sure. Branches are predicted based on historical data. The more data you have, and the better your branch predictors are tuned to your workload, the more accurate your predictions can be. Accurate branch prediction is particularly important in architectures with deep pipelines as a mispredict causes more instructions to be flushed out of the pipe. Bulldozer introduces a significantly deeper pipeline than its predecessor (more on this later), and thus branch prediction improvements are necessary.
In both Phenom II and Bulldozer, branches are predicted in the front end of the pipe alongside the fetch hardware. In Phenom II however, any stall in the fetch pipeline (e.g. fetching an instruction that wasn't in cache) would stop the whole pipeline including future branch predictions. Bulldozer decouples the branch prediction hardware from the fetch pipeline by way of a prediction queue. If there's a stall in the fetch pipeline, Bulldozer's branch prediction hardware is allowed to run ahead and continue making future predictions until the prediction queue is full.
We'll get to the effectiveness of this approach shortly.
Scheduling and Execution Improvements
As with Sandy Bridge, AMD migrated to a physical register file architecture with Bulldozer. Data is now only stored in one location (the physical register file) and is tracked via pointers back to the PRF as operations make their way through the execution engine. This is a move to save power as copying data around a chip is hardly power efficient.
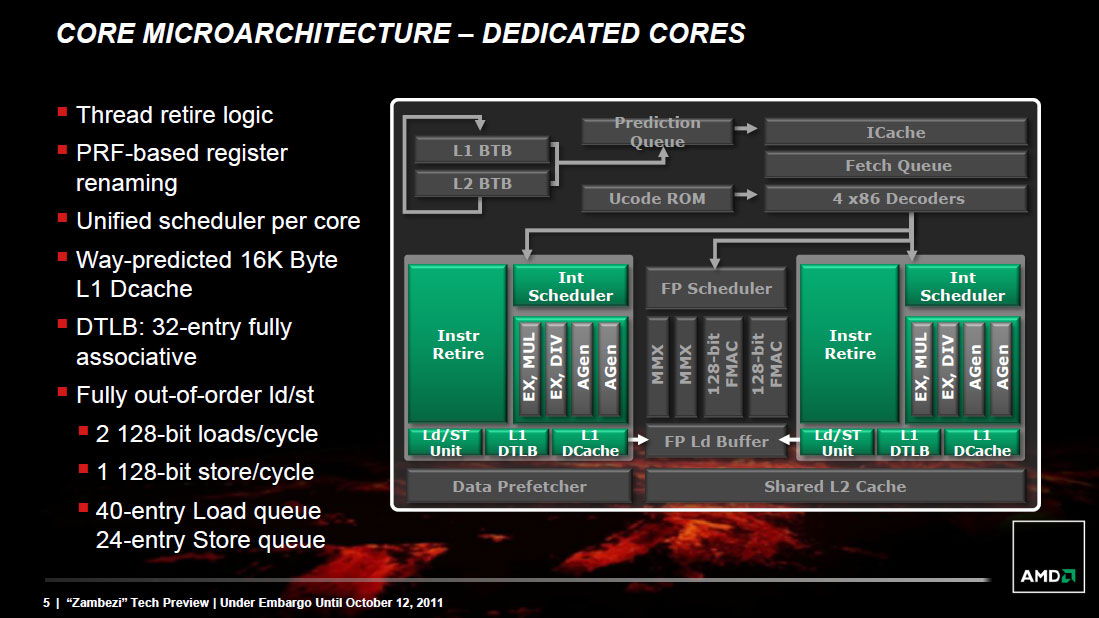
The buffers and queues that feed into the execution engines of the chip are all larger on Bulldozer than they were on Phenom II. Larger data structures allows for better instruction level parallelism when trying to execute operations out of order. In other words, the issue hardware in Bulldozer is beefier than its predecessor.
Unfortunately where AMD took one step forward in issue hardware, it does a bit of a shuffle when it comes to execution resources themselves. Let's start with the positive: Bulldozer's integer execution cores.
Integer Execution
Each Bulldozer module features two fully independent integer cores. Each core has its own integer scheduler, register file and 16KB L1 data cache. The integer schedulers are both larger than their counterparts in the Phenom II.
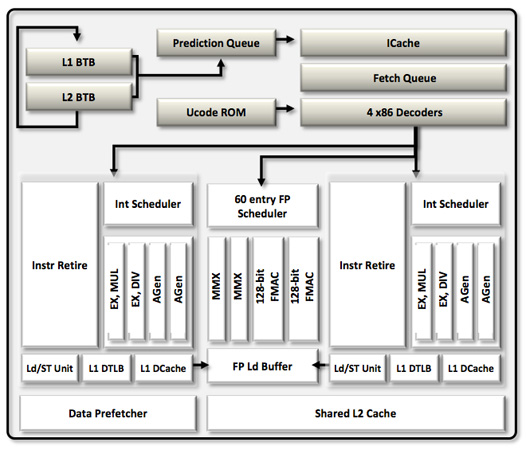
The biggest change here is each integer core now has two ports instead of three. A single integer core features two AGU/ALU ports, compared to three in the previous design. AMD claims the third ALU/AGU pair went mostly unused in Phenom II, and as a result it's been removed from Bulldozer.
With larger structures feeding into the integer cores, AMD should be able to have an easier time of making use of the integer units than in previous designs. AMD could, in theory, execute more integer operations per core in Phenom II however AMD claims the architecture was typically bound elsewhere.
The Shared FP Core
A single Bulldozer module has a single shared FP core for use by up to two threads. If there's only a single FP thread available, it is given full access to the FP execution hardware, otherwise the resources are shared between the two threads.
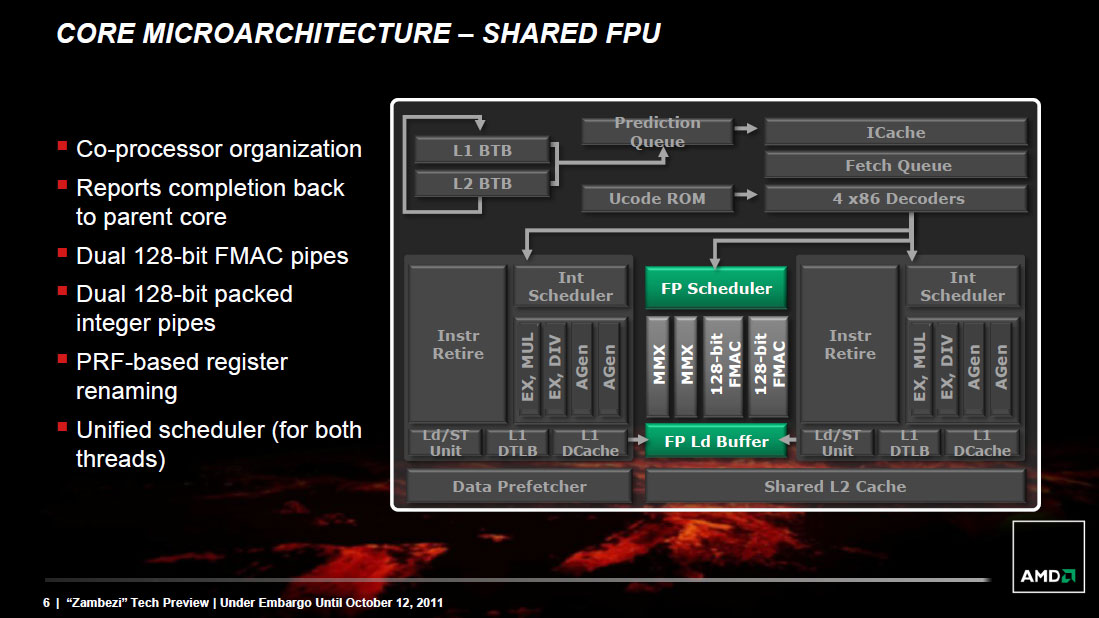
Compared to a quad-core Phenom II, AMD's eight-core (quad-module) FX sees no drop in floating point execution resources. AMD's architecture has always had independent scheduling for integer and floating point instructions, and we see the same number of execution ports between Phenom II cores and FX modules. Just as is the case with the integer cores, the shared FP core in a Bulldozer module has larger scheduling hardware in front of it than the FPU in Phenom II.
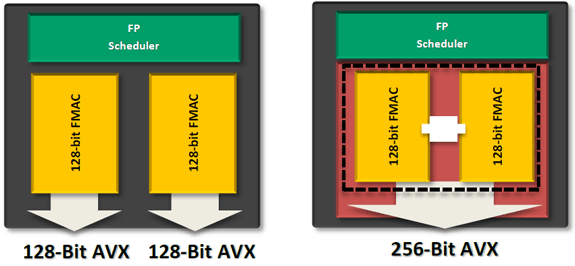
The problem is AMD had to increase the functionality of its FPU with the move to Bulldozer. The Phenom II architecture lacks SSE4 and AVX support, both of which were added in Bulldozer. Furthermore, AMD chose Bulldozer as the architecture to include support for fused multiply-add instructions (FMA). Enabling FMA support also increases the relative die area of the FPU. So while the throughput of Bulldozer's FPU hasn't increased over K8, its capabilities have. Unfortunately this means that peak FP throughput running x87/SSE2/3 workloads remains unchanged compared to the previous generation. Bulldozer will only be faster if newer SSE, AVX or FMA instructions are used, or if its clock speed is significantly higher than Phenom II.
Looking at our Cinebench 11.5 multithreaded workload we see the perfect example of this performance shuffle:

Despite a 9% higher base clock speed (more if you include turbo core), a 3.6GHz 8-core Bulldozer is only able to outperform a 3.3GHz 6-core Phenom II by less than 2%. Heavily threaded floating point workloads may not see huge gains on Bulldozer compared to their 6-core predecessors.
There's another issue. Bulldozer, at least at launch, won't have to simply outperform its quad-core predecessor. It will need to do better than a six-core Phenom II. In this comparison unfortunately, the Phenom II has the definite throughput advantage. The Phenom II X6 can execute 50% more SSE2/3 and x87 FP instructions than a Bulldozer based FX.
Since the release of the Phenom II X6, AMD's major advantage has been in heavily threaded workloads—particularly floating point workloads thanks to the sheer number of resources available per chip. Bulldozer actually takes a step back in this regard and as a result, you will see some of those same workloads perform worse, if not the same as the outgoing Phenom II X6.
Compared to Sandy Bridge, Bulldozer only has two advantages in FP performance: FMA support and higher 128-bit AVX throughput. There's very little code available today that uses AMD's FMA instruction, while the 128-bit AVX advantage is tangible.
Cache Hierarchy and Memory Subsystem
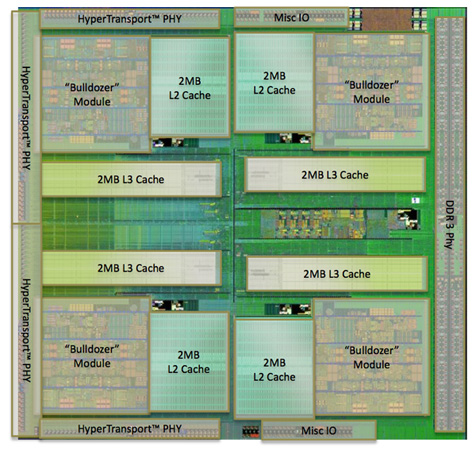
Each integer core features its own dedicated L1 data cache. The shared FP core sends loads/stores through either of the integer cores, similar to how it works in Phenom II although there are two integer cores to deal with now instead of just one. Bulldozer enables fully out-of-order loads and stores, an improvement over Phenom II putting it on parity with current Intel architectures. The L1 instruction cache is shared by the entire bulldozer module, as is the L2 cache.
The instruction cache is a large 64KB 2-way set associative cache, similar in size to the Phenom II's L1 cache but obviously shared by more "cores". A four-core Phenom II would have 256KB of total L1 I-Cache, while a four core Bulldozer will have half of that. The L1 data caches are also significantly smaller than Bulldozer's predecessor. While Phenom II offered a 64KB L1 D-Cache per core, Bulldozer only offers 16KB per integer core.

The L2 cache is much larger than what we saw in multi-core Phenom II designs however. Each Bulldozer module has a private 2MB L2 cache.
There's a single 8MB L3 cache that's shared among all Bulldozer modules on a chip. In its first incarnation, AMD has no plans to offer a desktop part without an L3 cache. However AMD indicated that the L3 cache was only really useful in server workloads and we might expect future Bulldozer derivatives (ahem, Trinity?) to forgo the L3 cache entirely as a result.
Cache accesses require more clocks in Bulldozer, due to a combination of size and AMD's desire to make Bulldozer a very high clock speed part...








430 Comments
View All Comments
psiboy - Monday, February 6, 2012 - link
What kind of retarded person would benchmark at 1024 x 768 on an enthusiast site where every one owns at least 1 1920 x 1080 monitor as they are 1. Dirt cheap and 2. The single biggest selling resolution for quite some time now... Real world across the board benches at 1920 x 1080 please!mumbles - Sunday, February 12, 2012 - link
I am not trying to discount the reviewer, the performance of Sandy Bridge, or games as a test of general application performance. I have no connection to company mentioned really anywhere on this site. I am just a software engineer with a degree in computer science who wants to let the world know why these metrics are not a good way to measure relative performance of different architectures.The world has changed drastically in the hardware world and the software world has no chance to keep up with it these days. Developing software implementations that utilize multiprocessors efficiently is extremely expensive and usually is not prioritized very well these days. Business requirements are the primary driver in even the gaming industry and "performs well enough on high end equipment(or in the business application world, on whatever equipment is available)" is almost always as good as a software engineer will be allowed time for on any task.
In performance minded sectors like gaming development and scientific computing, this results in implementations that are specific to hardware architectures that come from whatever company decides to sponsor the project. nVidia and Intel tend to be the ones that engage in these activities most of the time. Testing an application on a platform it was designed for will always yield better results than testing it on a new platform that nobody has had access to even develop software on. This results in a biased performance metric anytime a game is used as a benchmark.
In business applications, the concurrency is abstracted out of the engineer's view. We use messaging frameworks to process many small requests without having to manage concurrency at all. This is partly due to the business requirements changing so fast that optimizing anything results in it being replaced by something else instead. The underlying frameworks are typically optimized for abstraction instead of performance and are not intended to make use of any given hardware architecture. Obviously almost all of these systems use Java to achieve this, which is great because JIT takes care of optimizing things in real time for the hardware it is running on and the operations the software uses.
As games are developed for this architecture it will probably see far better benchmark results than the i series in those games which will actually be optimized for it.
A better approach to testing these architectures would be to develop tests that actually utilize the strengths of the new design rather than see how software optimized for some other architecture will perform. This is probably way more than an e-mag can afford to do, but I feel an injustice is being done here based on reading other people's comments that seem to put stock in this review as indication of actual performance of this architecture in the future, which really none of these tests indicate.
I bet this architecture actually does amazing things when running Java applications. Business application servers and gaming alike. Java makes heavy use of integer processing and concurrency, and this processor seems highly geared towards both.
And I just have to add, CINEBENCH is probably almost 100% floating point operations. This is probably why the Bulldozer does not perform any better than the Phenom II x4.
Also, AMD continues to impress on the value measurement. Check out the PassMarks per dollar on this bad boy:
http://www.cpubenchmark.net/cpu.php?cpu=AMD+FX-815...
djangry - Sunday, February 19, 2012 - link
Beware !!!! this chip is junk.I love Amd with all my heart and soul.
This fx chip is a black screen machine.
It breaks my heart to write this.
I am sending it back and trying to snag the last x6 phenom 2 's
I can find.
The fact that this chip is a dud is too well hidden.
When I called newegg they told me your the second one today with
horror stories about this chip.
msi would not come clean ...this chip is a turkey....
yet they were nice.
I will waste no more time with this nonsense.
my 754's work better.
We need honesty about the failure of this chip and the fact windows pulled the hot fix.
tlb bug part two.
Even linux users say after grub goes in Black screens.
Why isn't the industry coming clean on this issue.
Amd's 939 kicked Intel butt for 3 years- till they got it together,we need Amd ,but I do not like hidden issues and lack of disclosure.
Buyer beware!
AMDiamond - Monday, March 5, 2012 - link
Guys you are already upset because you spent your lunch money on Intel and even with higher this and that boards and memory AMD (even with half as much memory onboard [32GB] & Intel has [64GB] ) Intel is misquoting thier performance again...no matter what you say AMD= Dodge as to Intel=Cheverolet ..and when it gets down to AMD on the game versus Intel ...Intel has another hardcore asswhipping behind and ahead... its the same thing as a Dx4 processor(versus the pentium) even though Pentium had 1 comprehesion level higher ..when running the same programs DooM for example Pentium couldn't run DooM anywhere near as good as a simple DX4 amd..same stays true ...this Bulldozer has already broken unmatched records...AMD only lacks in 1 area..when you install windows the intel drivers already match at least 80 percent performance of Intel ...where AMD needs a specific narrow driver to run...once that driver is matched ..AMD =General Lee versus (Smokey & the) Bandits POS =Intel's comaro and its true ashamed that Intel even with 2x as much ddr3 memory ..cant even pickup the torch when AMD is smoking a Jet on the highway to hell for Intel -Hahahamauhahaha...sorry as intel qx9650 ahahahaahahahahahahahhahahahAMDiamond - Monday, March 5, 2012 - link
watch AMD take Diablo 3 (1 expansion by the next/it will be so ) Intel always lags hard on gaming compared to a weaker AMD class...point proven ...everest has alot of false benchmarks for Intel example NWN2 Phenom x3 8400 (triple core hasa bench 10880) yet a Intel Core 2 Duo e7500 has a bench of 12391 thats a 2.9ghtz cpu versus a 2.1ghtz CPU ..ok the kicker is intel is a dell amd is an aspire..DDR2 memory on the AMD and ddr3 memory on the intel ..all the intel bus features say higher (like they always do) but try running the same dammned video board on both systems then try running 132 NWN2 maps each medium size...no way the intel can do it ..the AMD can run the game editor and the maps at once..Intel is selling you a number AMD is selling you true frames per second..but your going to say oh but my Intel is a better core and this and that..ok now lets compare the price of the 2 systems...Intel was $2,500 the AMD was $400 ..why do you think that phenom just stomps the ass off that intel?(always has always will)zkeng - Wednesday, May 9, 2012 - link
I work as a building architect and use this CPU on my Linux workstation, in a Fractal Design define mini micro atx case, with 8GB ram and AMD radeon hd 6700 GPU.I usually have several applications running at the same time. Typically BricsCAD, a file manager, a web browser with a few tabs, Gimp image editor, music player, our business system and sometimes Virtualbox as well with a virtual machine.
I do allot of 3D projects and use Thea Render for photo rendering of building designs.
I use conky system monitor to watch the processor load and temperature.
These are my thoughts about the performance:
Runs cool and the noise level is low, because the processor can handle several applications without taking any stress at all.
Usually runs at only a few % average load for heavy business use (graphics and CAD in my case).
When working you get the feeling that this processor has good torque. Eight cores means most of the time every application can have at least one dedicated core and there is no lag even with lots of apps running. I think this will be a great advantage even if you use allot of older single core business applications.
The fact that this processor has rather high power consumption at full load is a factor to take into consideration if you put it under allot of constant load (and especially if you over clock).
For any use except really heavy duty CPU jobs (compiling software, photo rendering, video encoding) temporary load peaks will be taken care of in a few seconds, and you will typically see your processor working at only 1,4 GHz clock frequency. When idle the power consumption of this CPU is actually pretty low and temporary load peaks will make very little difference in total power consumption.
I sometimes photo render jobs for up to 32 hours and think of myself as a CPU demanding user, but still most of the time when my computer is running, it will be at idle frequency. I consider the idle power consumption to be by far the most important value of comparison between processors for 90% of all users. This is not considered in many benchmarks.
It is really nice to fire up Thea Render, use the power of all cores for interactive rendering mode while testing different materials on a design and then start an unbiased photo rendering and watch all eight cores flatten out with 100% load at 3,6 GHz.
Not only does this processor photo render slightly faster compared to my colleagues Intel Sandy Bridge. What is really nice is that i can run, lets say four renderings at the same time in the background, for a sun study, and then fire up BricsCAD to do drawing work while waiting. Trying to do this was a disaster with my last i5 processor. I forced me to do renderings during the night (out of business hours) or to borrow another work station during rendering jobs because my work station was locked up by more than one instance of the rendering application.
....................
To summarize, this is by far the best setup (CPU included) I have ever used on a work station. Affordable price, reasonably small case, low noise level, completely modular, i will be able to upgrade in the future without changing my am3+ mother board. The CPU is fast and offers superb multi tasking. This is the first processor I have ever used that also offers good multi tasking under heavy load (photo rendering + cad at the same time)
This is a superb CPU for any business user who likes to run several apps at the same time. It is also really fast with multi core optimized software.
AMD FX-8150 is my first AMD desktop processor and I like it just as much as I dislike their fusion APUs on the laptop market. Bulldozer has all the power where it is best needed, perfectly adopted to my work flow.
la'quv - Wednesday, August 29, 2012 - link
I don't know what it is with all this hype destroying amd's reputation. The bulldozer architecture is the best cpu design I have seen in years. I guess the underdog is not well respected. The bulldozer architecture has more pipelines and schedulers that the Core 2. The problem is code is compiled intel optimized not amd optimized. These benchmarks for a bunch of applications I don't use have no bearing on my choice to by a cpu, there are some benchmarks where an i5 will outperform and i7 so what valid comparison's are we making here. The bulldozer cpu's are dirt cheap and people expect them to be cheaper and don't require high clock speed ram and run on cheaper motherboards. AMD is expected to keep up with intel on the manufacturing process. Cutting corners and going down to 32nm then 22nm as quickly as possible does not produce stable chips. I have my kernel compiled AMD64 and it is not taxed by anything I am doing.brendandaly711 - Friday, September 6, 2013 - link
AMD still hasn't been able to pull out of the rut that INTEL left them in after the Sandy Bridge breakthrough. I am a (not so proud) owner of an FX-4100 in one of my pc's and an 8150 in the other. The 4100 compares to an ivy bridge i3 or a sandy bridge i5. I will give AMD partial credit, though, the 8150 performs at the ivy bridge's i5 level for almost identical prices.Nfarce - Sunday, September 20, 2020 - link
And here we are in 2020 some 9 years after this review and 7 years after your comment and AMD still hasn't been able to equal Intel as an equal gaming performance contender. AMD's only saving face is the fact that now higher resolution demands of 1440p and now 4K essentially make any modern game CPU bound and more dependent on the GPU power.BlueB - Wednesday, October 5, 2022 - link
I always come back to this review every few years just to have a good laugh looking back at this turd architecture, and especially at genius comments like:"You don't get the architecture"; "it's a server CPU"; "it's because Windows scheduler"; etc., etc.
No, it wasn't any of those things. The CPU's a turd. It was a turd then, it's a turd now, and it will be a turd no matter what. It wasn't more future-proof than either Sandy or Ivy, 2600Ks from 11 years ago still run circles around it in both single and multi-threaded apps, old and new. The class action lawsuit against AMD was the cherry on top.
It really never gets old to read through the golden comment section here and chuckle at all the visionary comments which tried to defend this absolute failure of an architecture. It's an excellent article, and together with its comment section will always have a special place in my heart.