Qualcomm's New Snapdragon S4: MSM8960 & Krait Architecture Explored
by Brian Klug & Anand Lal Shimpi on October 7, 2011 12:35 PM EST- Posted in
- Smartphones
- Snapdragon
- Arm
- Qualcomm
- Krait
- MDP
- Mobile
- SoCs
The Adreno 225 GPU
Qualcomm has historically been pretty silent about its GPU architectures. You'll notice that specific details of Adreno GPU execution resources have been absent from most of our SoC comparisons. Starting with MSM8960 however, this is starting to change.
The MSM8960 uses a current generation Adreno GPU with a couple of changes. Qualcomm calls this GPU the Adreno 225, a follow-on to Adreno 220. Subsequent Krait designs will use Adreno 3xx GPUs based on a brand new architecture.
As we discussed in our Samsung Galaxy S 2 review, Qualcomm's Adreno architecture is a tile based immediate mode renderer with early-z rejection. By Qualcomm's own admission, Adreno is somewhere in the middle of the rendering spectrum between IMRs and Imagination Technologies' TBDR architectures. One key difference is Adreno's tiling isn't as fine grained as IMG's.
Architecturally the Adreno 225 and 220 are identical. Adreno 2xx is a DX9-class unified shader design. There's a ton of compute on-board with eight 4-wide vector units and eight scalar units. Each 4-wide vector unit is capable of a maximum of 8 MADs per clock, while each scalar unit is similarly capable of 2 MADs per clock. That works out to 160 floating point operations per clock, or 32 GFLOPS at 200MHz.
Update: Qualcomm has clarified the capabilities of its 4-wide Vector ALUs. Similar to the PowerVR SGX 543, each 4-wide vector ALU is capable of four MADs (one per component). The scalar units cannot be combined to do any MADs, although they are helpful we haven't really been tracking those in this table (IMG has something similar) so we've excluded them for now.
| Mobile SoC GPU Comparison | |||||||||||
| Adreno 225 | PowerVR SGX 540 | PowerVR SGX 543 | PowerVR SGX 543MP2 | Mali-400 MP4 | GeForce ULP | Kal-El GeForce | |||||
| SIMD Name | - | USSE | USSE2 | USSE2 | Core | Core | Core | ||||
| # of SIMDs | 8 | 4 | 4 | 8 | 4 + 1 | 8 | 12 | ||||
| MADs per SIMD | 4 | 2 | 4 | 4 | 4 / 2 | 1 | ? | ||||
| Total MADs | 32 | 8 | 16 | 32 | 18 | 8 | ? | ||||
| GFLOPS @ 200MHz | 12.8 GFLOPS | 3.2 GFLOPS | 6.4 GFLOPS | 12.8 GFLOPS | 7.2 GFLOPS | 3.2 GFLOPS | ? | ||||
| GFLOPS @ 300MHz | 19.2 GFLOPS | 4.8 GFLOPS | 9.6 GFLOPS | 19.2 GFLOPS | 10.8 GFLOPS | 4.8 GFLOPS | ? | ||||
Looking at the table above you'll see that this is the same amount of computing power than even IMG's PowerVR SGX 543MP2. However as we've already seen in our tests, Adreno 220 isn't anywhere near as quick.
Shader compiler efficiency and data requirements to actually populate a Vec4+1 array are both unknowns, and I suspect both significantly gate overall Adreno performance. There's also the fact that the Adreno 22x family only has two TMUs compared to four in the 543MP2, limiting texturing performance. Combine that with the fact that most Adreno 220 GPUs have been designed into single-channel memory controller systems and you've got a recipe for tons of compute potential limited by other bottlenecks.
With Adreno 225 Qualcomm improves performance along two vectors, the first being clock speed. While Adreno 220 (used in the MSM8660) ran at 266MHz, Adreno 225 runs at 400MHz thanks to 28nm. Secondly, Qualcomm tells us Adreno 225 is accompanied by "significant driver improvements". Keeping in mind the sheer amount of compute potential of the Adreno 22x family, it only makes sense that driver improvements could unlock a lot of performance. Qualcomm expects the 225 to be 50% faster than the outgoing 220
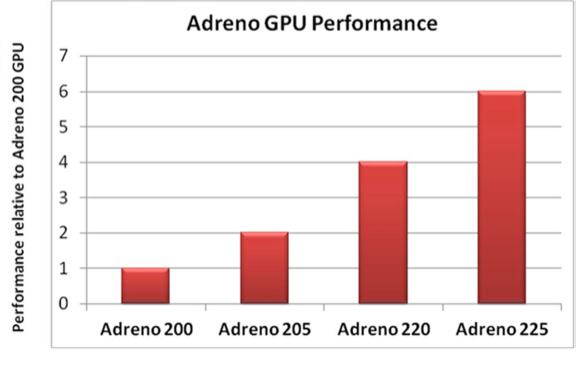
Qualcomm claims that MSM8960 will be able to outperform Apple's A5 in GLBenchmark 2.x at qHD resolutions. We'll have to wait until we have shipping devices in hand to really put that claim to the test, but if true it's good news for Krait as the A5 continues to be the high end benchmark for mobile GPU performance.
While Adreno 225 is only Direct3D feature level 9_3 compliant, Qualcomm insisted that when the time is right it will have a D3D11 capable GPU using its own IP - putting to rest rumors of Qualcomm looking to license a third party GPU in order to be competitive in Windows 8 designs. Although Qualcomm committed to delivering D3D11 support, it didn't commit to a timeframe.








108 Comments
View All Comments
DanNeely - Friday, October 7, 2011 - link
Static ram (the kind used in CPU caches) has always been much faster than the dynamic ram used for main system memory.SRAM uses a block of a half dozen transistors to store a bit as a stable logic state; as a result it can operate as fast as any other transistor based device in an IC. The number of clock cycles a cache bank needs to complete an access operation is primarily a factor of its size, both because it takes more work to select a specific part and because signalling delays due to the speed of electric signals through the chip become significant at gigahertz speeds. Size isn't the only speed factor in how fast a cpu cache operators; higher associativity levels can improve worst case behavior (by reducing misses due to pathalogical memory access patterns) significantly at the cost of slowing all operations slightly.
DRAM has a significantly different design, it only uses a single transistor per bit and stores the data in a paired capacitor. This allows for much higher memory capacities in a single chip and much lower costs/GB as a result. The catch is that reading the capacitors charge level and then recharging it after the check takes significantly longer. The actual memory cells in a DDR3-1600 chip are only operating at 200mhz (up from 100-133mhz a decade ago); other parts of the chips operate much faster as they access large numbers of memory cells in parallel to keep the much faster memory bus fed.
Blaster1618 - Saturday, October 8, 2011 - link
Thank you for such a clear and thorough response.MonkeyPaw - Friday, October 7, 2011 - link
Isn't it amazing how these low-power architectures are surpassing Atom in both power and performance? Atom isn't even an OoO architecture. Windows 8 and OS X Lion will be allow these architectures in netbooks and ultrabooks before we know it, and Intel's value-stripping at the low-end will finally die a terrible death.partylikeits1999 - Saturday, October 8, 2011 - link
Intel will be in very big trouble unless FinFet can get Atom's power down in the same sub 4W range as this next round of quad core chipsets from nVidia, Qualcomm and TI.Wilco1 - Saturday, October 8, 2011 - link
Even with FinFet it's impossible Atom will run at 4GHz which it needs to get comparable performance as an A15 or Krait at 2.5GHz. And in less than 2W. Atom has been dead in the water for a while now - it cannot keep up with ARM out-of-order cores on performance, power consumption or integration despite Intel's process advantage.Tomasthanes - Friday, October 7, 2011 - link
Yes, I could go to Google. It's just better journalism to define acronyms (even common ones) as you use them.Baron Fel - Friday, October 7, 2011 - link
system on a chip. At this point for Anand it would be like writing CPU as central processing unit.bjacobson - Saturday, October 8, 2011 - link
silly me been saying silicon on chip in my head all these years never stopped to think it through >.<bjacobson - Friday, October 7, 2011 - link
very exciting. Soon I won't have any need of a dedicated desktop except for gaming or a laptop except for business.Zingam - Saturday, October 8, 2011 - link
So you basically need a desktop and a laptop?