Arm's Cortex-A76 CPU Unveiled: Taking Aim at the Top for 7nm
by Andrei Frumusanu on May 31, 2018 3:01 PM EST- Posted in
- CPUs
- Arm
- Smartphones
- Mobile
- SoCs
- Cortex-A76
Cortex A76 µarch - Frontend
Starting off with a rough overview of the Cortex A76 microarchitectural diagram we see the larger functional blocks. The A76 doesn’t look too different than other Arm processors in this regard and the differences come only with details that Arm is willing to divulge. To overly simplify it, this is a superscalar out-of-order core with a 4-wide decode front-end with 8 execution ports in the backend with a total implementation pipeline depth of 13 stages with the execution latencies of a 11 stage core.

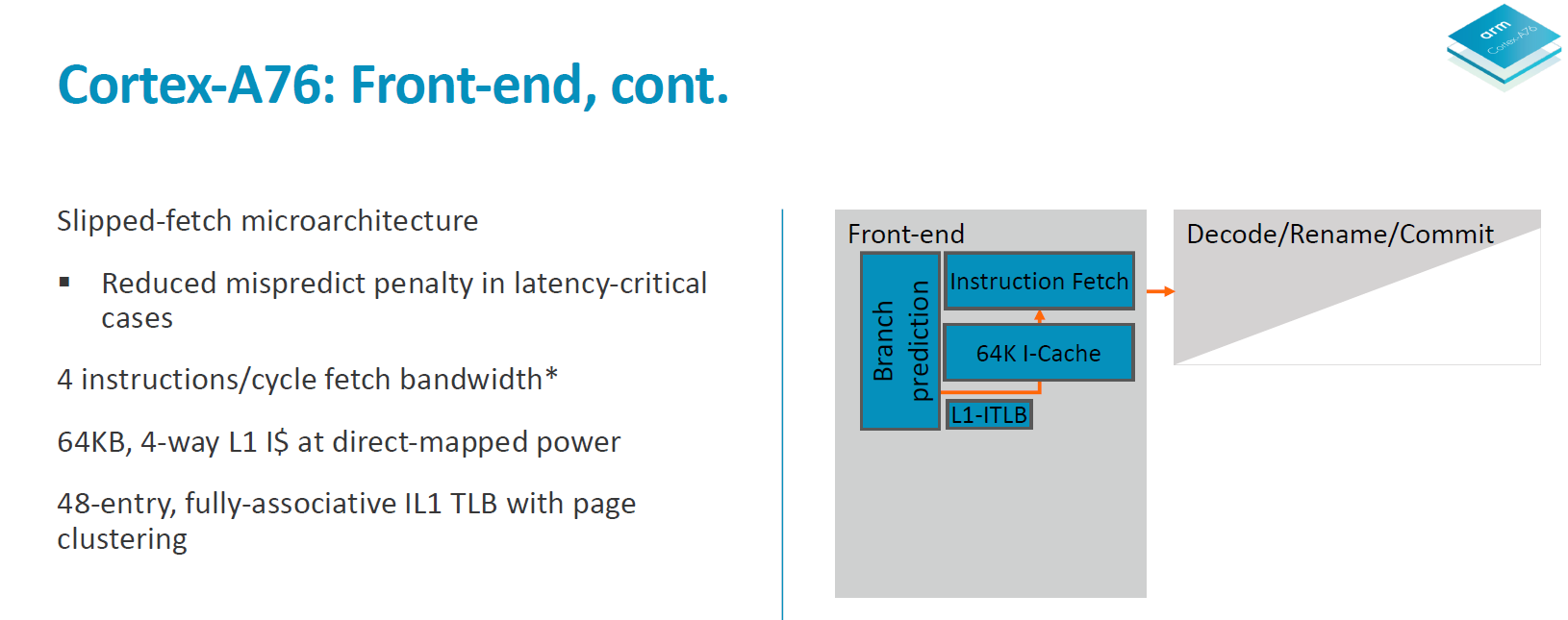
In the front-end, Arm has created a new predict/fetch unit that it calls a “predict-directed fetch”, meaning the branch prediction unit feeds into the instruction fetch unit. This is a divergence from past Arm µarches and it allows for both higher performance and lower power consumption.

The branch prediction unit is what Arm calls a first in the industry in adopting a hybrid indirect predictor. The predictor is decoupled from the fetch unit and its supporting large structures operate separate from the rest of the machine – likely what this means is that it will be easier to clock-gate during operation to save on power. The branch predictor is supported by 3-level branch target caches; a 16-entry nanoBTB, a 64-entry microBTB and a 6000 entry main BTB. Arm claimed back in the A73 and A75 generations of branch predictors were able to nearly predict all taken branches so this new unit in the A76 seems to be one level above that in capability.
The branch unit operates at double the bandwidth of the fetch unit – it operates on 32B/cycle meaning up to 8 32b instructions per cycle. This feeds a fetch queue in front of the instruction fetch consisting of 12 “blocks”. The fetch unit operates at 16B/cycle meaning 4 32b instructions. The branch unit operating at double the throughput makes it possible to get ahead of the fetch unit. What this serves is that in the case of a mispredict it can hide branch bubbles in the pipeline and avoid stalling the fetch unit and the rest of the core. The core is said to able to cope with up to 8 misses on the I-side.
I mentioned at the beginning that the A76 is a 13-stage implementation with the latency of an 11-stage core. What happens is that in latency-critical paths the stages can be overlapped. One such cycle happens between the second cycle of the branch predict path and the first cycle of the fetch path. So effectively while there’s 4 (2+2) pipeline stages on the branch and fetch, the core has latencies of down to 3 cycles.
On the decode and rename stages we see a throughput of 4 instructions per cycle. The A73 and A75 were respectively 2 and 3-wide in their decode stages so the A76 is 33% wider than the last generation in this aspect. It was curious to see the A73 go down in decode width from the 3-wide A72, but this was done to optimise for power efficiency and “leanness” of the pipeline with goals of improving the utilisation of the front-end units. With the A76 going 4-wide, this is also Arms to date widest microarchitecture – although it’s still extremely lean when putting it into juxtaposition with competing µarches from Samsung or Apple.
The fetch unit feeds a decode queue of up to 16 32b instructions. The pipeline stages here consist of 2 cycles of instruction align and decode. It looks here Arm decided to go back to a 2-cycle decode as opposed to the 1-cycle unit found on the A73 and A75. As a reminder the Sophia cores still required a secondary cycle on the decode stage when handling instructions utilising the ASIMD/FP pipelines so Arm may have found other optimisation methods with the A76 µarch that warranted this design decision.
The decode stage takes in 4 instructions per cycle and outputs macro-ops at an average ratio of 1.06Mops per instruction. Entering the register rename stage we see heavy power optimisation as the rename units are separated and clock gated for integer/ASIMD/flag operations. The rename and dispatch are a 1 cycle stage which is a reduction from the 2-cycle rename/dispatch from the A73 and A75. Macro-ops are expanded into micro-ops at a ratio of 1.2µop per instruction and we see up to 8µops dispatched per cycle, which is an increase from the advertised 6µops/cycle on the A75 and 4µops/cycle on the A73.
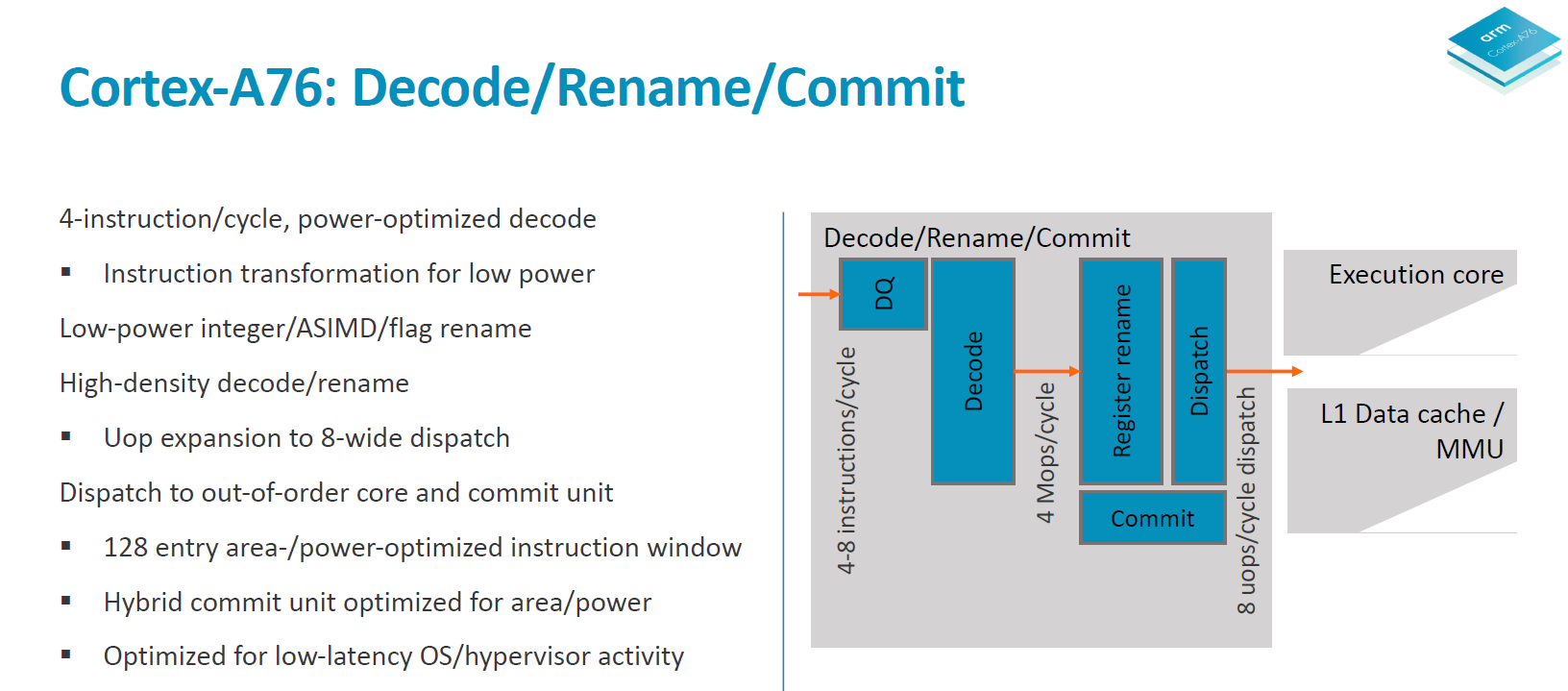
The out-of-order window commit size of the A76 is 128 and the buffer is separated into two structures responsible for instruction management and register reclaim, called a hybrid commit system. Arm here made it clear that it wasn’t focusing on increasing this aspect of the design as it found it as a terrible return on investment when it comes to performance. It is said that the performance scaling is 1/7th – meaning a 7% increase of the reorder buffer only results in a 1% increase in performance. This comes at great juxtaposition compared to for example Samsung's M3 cores with a very large 224 ROB.
As a last note on the front-end, Arm said to have tried to optimised the front-end for lowest possible latency for hypervisor activity and system calls, but didn’t go into more details.








123 Comments
View All Comments
id4andrei - Thursday, May 31, 2018 - link
Apple has the manpower and funds to spend extensively for a huge chip for they are free to do things for their own glory. QCOMM designs chip for others to use and must design for price points. They must do so efficiently and maximize yields. ARM provides base designs that others can outright use or customize, you can't really blame ARM here. NVIDIA has no modem.syxbit - Thursday, May 31, 2018 - link
I get that, but you're missing the point. Sure, the budget phones have a strict budget.An $800 Android flagship should not be tight on the SoC budget. If QCOMM sold an ultra high snapdragon that could compete with the A12 you had better believe the Galaxy S10 and Pixel 3 phones would pay to use it.
truckasaurus - Thursday, May 31, 2018 - link
Apple has the convenience of designing to a very specific application. Qualcomm ultimately has to create something that can go into many platforms that are defined no more completely than 'high-end mobile'. That's like asking why the 3.5L V6 that's in most of Toyota's vehicles only makes 268 hp, but in the Lotus Evora 400, which uses the same engine, makes 400 hp. It's because it has been tweaked for a very specific application.serendip - Thursday, May 31, 2018 - link
Then they should sell supercharger kits for Qualcomm chips ;-)That is how the Evora V6 gets 400 hp compared to 280-300 hp on the latest non-turbo versions of that V6. The twin turbo version of that engine on the Lexus LS makes over 450 hp too.
truckasaurus - Thursday, May 31, 2018 - link
That's essentially what I'm getting at. Qualcomm makes the generic version of the engine that can go into a sedan, an SUV, a coupe, and a convertible and adequately power all of them. Apple says, we're only going to make 1 model of sports car and one large luxury sedan, and because we know exactly what our constraints are on these two platforms, we can add a turbo or a supercharger, we can tweak the timing, we can put a high-flow exhaust on it, etc.Pneumothorax - Friday, June 1, 2018 - link
Your point would make sense if the 845 were being used in low end Androids. Since it's pretty much only being used in high end designs, all out performance should've been the goal.syxbit - Thursday, May 31, 2018 - link
None of what you're saying makes sense. I simply think QCOMM and the rest are behind Apple because they can't do as good a job as Apple. It isn't because the market doesn't exist or because they need to build flexible designs.SirPerro - Friday, June 1, 2018 - link
Oh but many of us reading this conversation think all that really makes sense, and it really is because the market doesn't exist or because they need to build flexible designs.The car engine analogy was pretty great. It's exactly like that.
Threska - Thursday, May 31, 2018 - link
True. What Apple is good at is showing the potential for what's possible. Other's may have their reasons for not reaching it, but at least none can say it's not possible.shadowx360 - Thursday, May 31, 2018 - link
A lot of it comes down to power consumption. Samsung managed to get close to the A10 performance but at the cost of much higher power draw. With a 4 wide decoder instead of 6 wide, ARM is able to keep power usage in check and if their claims are to be believed, A10 performance at half the power is probably more desirable to the average consumer than A11/A12 performance at Snapdragon 810 levels of thermal throttle.